ผศ.ดร. วิภาดา เวทย์ประสิทธิ์ 450-101 Management Information System Decision Support System ผศ.ดร. วิภาดา เวทย์ประสิทธิ์ Office :CS320, Computer Science Building Email :wwettayaprasit@yahoo.com Website :http://staff.cs.psu.ac.th/wiphada Phone :0-7428-8596
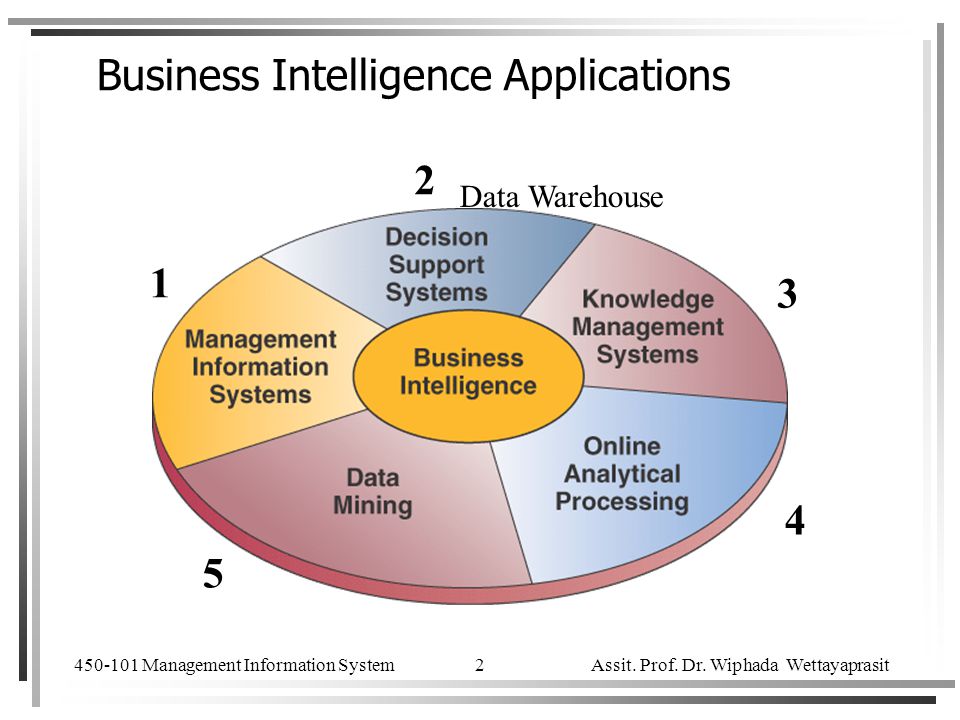
Business Intelligence Applications 2 Data Warehouse 1 3 4 5
Levels of Managerial Decision Making
Decision Structure Structured (operational) Unstructured (strategic) The procedures to follow when decision is needed can be specified in advance Unstructured (strategic) It is not possible to specify in advance most of the decision procedures to follow Semi-structured (tactical) Decision procedures can be pre-specified, but not enough to lead to the correct decision
Information Quality Information products made more valuable by their attributes, characteristics, or qualities Information that is outdated, inaccurate, or hard to understand has much less value Information has three dimensions Time Content Form
Attributes of Information Quality
Decision Support in Business Companies are investing in data-driven decision support application frameworks to help them respond to Changing market conditions Customer needs This is accomplished by several types of Management information Decision support Other information systems
1 Management Information Systems The original type of information system that supported managerial decision making Produces information products that support many day-to-day decision-making needs Produces reports, display, and responses Satisfies needs of operational and tactical decision makers who face structured decisions
2 Decision Support Systems Management Information Systems Decision Support Systems Decision support provided Provide information about the performance of the organization Provide information and techniques to analyze specific problems Information form and frequency Periodic, exception, demand, and push reports and responses Interactive inquiries and responses Information format Prespecified, fixed format Ad hoc, flexible, and adaptable format Information processing methodology Information produced by extraction and manipulation of business data Information produced by analytical modeling of business data
Decision Support Systems Decision support systems use the following to support the making of semi-structured business decisions Analytical models Specialized databases A decision-maker’s own insights and judgments An interactive, computer-based modeling process DSS systems are designed to be ad hoc, quick-response systems that are initiated and controlled by decision makers
DSS Components
Decision Support Trends The emerging class of applications focuses on Personalized decision support Modeling Information retrieval Data warehousing What-if scenarios Reporting
DSS Model Base Model Base Spreadsheet Examples A software component that consists of models used in computational and analytical routines that mathematically express relations among variables Spreadsheet Examples Linear programming Multiple regression forecasting Capital budgeting present value
Using Decision Support Systems Using a decision support system involves an interactive analytical modeling process Decision makers are not demanding pre-specified information They are exploring possible alternatives What-If Analysis Observing how changes to selected variables affect other variables
Data Visualization Systems DVS Represents complex data using interactive, three-dimensional graphical forms (charts, graphs, maps) Helps users interactively sort, subdivide, combine, and organize data while it is in its graphical form
Analysis of Customer Demographics
Data Warehouse คลังข้อมูล หมายถึง.... หลักการหรือวิธีการ เพื่อรวมระบบ สารสเทศเพื่อ การประมวลผลรายการข้อมูลที่เกิดขึ้น ในแต่ละวันแต่ละสายงาน มารวมเป็นหน่วยเดียวกัน เพื่อสนับสนุนการตัดสินใจให้มีประสิทธิภาพมากยิ่งขึ้น คลังข้อมูล หมายถึง.... ข้อมูลในแหล่งข้อมูลหลายๆแหล่ง เพื่อประกอบการตัดสินใจให้มีประสิทธิภาพมากยิ่งขึ้น คลังข้อมูล ไม่ใช่ผลิตภัณฑ์ หรือระบบสำเร็จรูป คลังข้อมูล มีความเป็นส่วนตัวของแต่ละองค์กร (Organization Customized System)
Multi-Tiered Architecture Data Warehouse Extract Transform Load Refresh OLAP Engine Analysis Query Reports Data mining Monitor & Integrator Metadata Data Sources Front-End Tools Serve Data Marts Operational DBs other sources Data Storage OLAP Server
คุณลักษณะของคลังข้อมูล 1. Subject-Oriented 2. Integrated 3. Time-Variant 4. Non-Volatile
คุณลักษณะของคลังข้อมูล 1. Subject-Oriented ข้อมูลถูกจัดกลุ่มให้เหมาะสมกับการสืบค้น จัดตามประเด็นหลักขององค์กร เช่น ลูกค้า สินค้า ยอดขาย ข้อมูลจะ....ไม่ถูกจัดตามหน้าที่การงาน....ของโปรแกรมใดโปรแกรมหนึ่ง เช่น การควบคุมคลังสินค้า การออกใบกำกับภาษี 2. Integrated จัดข้อมูลให้อยู่ในรูปแบบเดียวกัน จากแหล่งข้อมูลหลายแหล่ง
คุณลักษณะของคลังข้อมูล 3. Time-Variant ข้อมูลต้องมีความถูกต้อง เพราะเก็บไว้ใช้นาน 5-10 ปี 4. Non-Volatile การปรับปรุงข้อมูลเป็นการเพิ่มข้อมูลใหม่เข้าไปเรื่อยๆ ไม่ใช่การแทนที่ข้อมูลเก่า ข้อมูลในคลังข้อมูล....ไม่จำเป็น...ต้องทำการ Normalize เหมือนในฐานข้อมูล (Data based)
ข้อดีของคลังข้อมูล 1. ให้ผลตอบแทนในการลงทุนสูง 2. ได้เปรียบคู่แข่ง วิเคราะห์ข้อมูลเพื่อกำหนดเป็นแผนกลยุทธ์ได้ก่อนคู่แข่ง เช่นพฤติกรรมผู้บริโภค 3. เพิ่มประสิทธิภาพในการตัดสินใจ มีข้อมูลครบถ้วนจากอดีตจนถึงปัจจุบัน
ข้อเสียของคลังข้อมูล 1. ขั้นตอนการกรองข้อมูลใช้เวลานาน ต้องอาศัยผู้ที่มีความชำนาญในการกรองข้อมูล 2. แนวโน้มในการกรองข้อมูลเพิ่มมากขึ้นเรื่อยๆ เพิ่มความซับซ้อนให้กระบวนการทำงาน 3.ใช้เวลานานในการพัฒนาคลังข้อมูล 4.ระบบคลังข้อมูลมีความซับซ้อนสูง
3 Knowledge Management Successful knowledge management Creates techniques, technologies, systems, and rewards for getting employees to share what they know Makes better use of accumulated workplace and enterprise knowledge
Knowledge Management Techniques
Knowledge Management Systems (KMS) A major strategic use of IT Manages organizational learning and know-how Helps knowledge workers create, organize, and make available important knowledge Makes this knowledge available wherever and whenever it is needed Knowledge includes Processes, procedures, patents, reference works, formulas, best practices, forecasts, and fixes
Knowledge Management การจัดการความรู้
ความรู้แบบชัดแจ้ง (Explicit Knowledge) 20% อธิบายได้ แต่ยังไม่ถูกนำไปบันทึก อธิบายได้ แต่ไม่อยากอธิบาย อธิบายไม่ได้ ความรู้โดยนัย/แบบซ่อนเร้น (Tacit Knowledge) 80%
เกลียวความรู้ SECI Model ใช้ตัวอย่าง ลงมือปฏิบัติ S E I C สื่อ/ประชุม ทรัพย์สิน
TUNA Model Knowledge Sharing (KS) Knowledge Knowledge Assets (KA) ส่วนกลางลำตัว ส่วนที่เป็น “หัวใจ” ให้ความสำคัญกับการแลกเปลี่ยนเรียนรู้ ช่วยเหลือ เกื้อกูลซึ่งกันและกัน (Share & Learn) TUNA Model (Thai –UNAids) Knowledge Sharing (KS) Knowledge Vision (KV) Knowledge Assets (KA) ส่วนหาง สร้างคลังความรู้ เชื่อมโยงเครือข่าย ประยุกต์ใช้ ICT “สะบัดหาง” สร้างพลังจาก CoPs ส่วนหัว ส่วนตา มองว่ากำลังจะไปทางไหน ต้องตอบได้ว่า “ทำ KM ไปเพื่ออะไร”
การจัดการความรู้ การบริหารจัดการ เพื่อให้.. “คน” ที่ต้องการใช้ความรู้ Right Knowledge…. Right People… Right Time… การบริหารจัดการ เพื่อให้.. “คน” ที่ต้องการใช้ความรู้ ได้รับ..ความรู้ที่ต้องการใช้ ในเวลา..ที่ต้องการ เพื่อให้บรรลุเป้าหมายการทำงาน (Source: APQC)
การบริการชุมชน จังหวัด อำเภอ ตำบล
ทีมงานพัฒนาการจัดการความรู้ คุณเอื้อ เป็นผู้บริหารระดับสูงทำหน้าที่จัดการความรู้ขององค์กร คุณอำนวย เชื่อมโยงคน สร้างความสัมพันธ์ต่อกัน คุณกิจ ผู้ที่รับผิดชอบตามหน้าที่ของตน คุณลิขิต ผู้ทำหน้าที่จดบันทึก สกัดองค์ความรู้ คุณวิศาสตร์ ออกแบบระบบไอที
4 Online Analytical Processing OLAP Enables managers and analysts to examine and manipulate large amounts of detailed and consolidated data from many perspectives Done interactively, in real time, with rapid response to queries
Multidimensional Data Sales volume as a function of product, month, and region Hierarchical summarization paths Region Industry Region Year Category Country Quarter Product City Month Week Office Day Product Dimensions: Product, Location, Time Month
A Sample Data Cube All, All, All Dimensions: Product,Date,Country Date Total annual sales of TV in U.S.A. Date Product Country All, All, All sum TV VCR PC 1Qtr 2Qtr 3Qtr 4Qtr U.S.A Canada Mexico
Cuboids Corresponding to the Cube all 0-D(apex) cuboid country product date 1-D cuboids product,date product,country date, country 2-D cuboids 3-D(base) cuboid product, date, country
Browsing a Data Cube Visualization OLAP capabilities Interactive manipulation
Online Analysis Processing (OLAP) กระบวนการประมวลผลข้อมูลทางคอมพิวเตอร์ ที่ช่วยให้วิเคราะห์ข้อมูลในมิติต่างๆ (Multidimensional Data Analysis) การดำเนินการกับ OLAP Roll up Drill Down Slice Dice
Typical OLAP (on-line analytical processing) Operations 1 Roll up (drill-up): summarize data by climbing up hierarchy or by dimension reduction มีการรวมหรือสรุปค่า 2 Drill down (roll down): reverse of roll-up from higher level summary to lower level summary or detailed data, or introducing new dimensions มีการกระจายค่าในรายละเอียดมากขึ้น ตามชนิดข้อมูล
Fact Table
Roll Up and Drill Down
Typical OLAP Operations 3 Slice เลือกพิจารณา...ผลลัพธ์...บางส่วนที่เราสนใจ ตัดค่าตาม Dimension 4 Dice เลือกพิจารณา...พลิก Dimension... ให้ตรงตามความต้องการของผู้ใช้ เช่น จากมุมมอง Shop-Product-Type ไปเป็น Date-Product-Type
Dimension
5 Data Mining Provides decision support through knowledge discovery Analyzes vast stores of historical business data Looks for patterns, trends, and correlations Goal is to improve business performance
Data Mining (เหมืองข้อมูล) เหมืองข้อมูล เป็นเครื่องมือที่ช่วยให้ผู้ใช้เข้าถึงข้อมูลได้โดยตรงจากฐานข้อมูลขนาดใหญ่ เหมืองข้อมูล เป็นเครื่องมือ และ Application ที่สามารถแสดงผลการวิเคราะห์ข้อมูลทางสถิติได้ เหมืองข้อมูล หมายถึงการวิเคราะห์ข้อมูล เพื่อแยกประเภท จำแนกรูปแบบและความสัมพันธ์ของข้อมูลจากคลังข้อมูลหรือฐานข้อมูลขนาดใหญ่ นำสารสนเทศไปใช้ในการตัดสินใจธุรกิจ ได้องค์ความรู้ใหม่ (Knowledge Discovery) อาจอยู่ในรูปแบบของกฎเกณฑ์ (Rule)
Data Mining Process
คุณลักษณะของเหมืองข้อมูล 1. ชี้แนวทางการตัดสินใจและคาดการณ์ผลลัพธ์ 2. เพิ่มความเร็วในการวิเคราะห์ข้อมูล จากฐานข้อมูลขนาดใหญ่ 3. ค้นหาส่วนประกอบที่ซ่อนอยู่ในเอกสาร รวมถึงความสัมพันธ์ระหว่างส่วนประกอบต่างๆ 4. จัดกลุ่มเอกสารตามหัวข้อต่างๆตามนโยบายบริษัท
เทคนิคการทำเหมืองข้อมูล 5.1. Classification 5.2. Clustering 5.3. Association 5.4. Visualization
เทคนิคการทำเหมืองข้อมูล 5.1. Classification : เทคนิคในการจำแนกกลุ่มข้อมูลด้วย คุณลักษณะต่างๆที่ได้มีการกำหนดไว้แล้ว สร้างแบบจำลองเพื่อการพยากรณ์ค่าข้อมูล (Predictive Model) ในอนาคต เรียกว่า ......Supervised Learning มี 2 รูปแบบ Tree Induction Neural Network 5.2. Clustering : เทคนิคในการจำแนกกลุ่มข้อมูลใหม่ที่มีลักษณะคล้ายกันไว้กลุ่มเดียวกัน โดยไม่มีการจัดกลุ่มข้อมูลตัวอย่างไว้ล่วงหน้า เรียกว่า .......Unsupervised Learning
เทคนิคการทำเหมืองข้อมูล 5.3. Association : เทคนิคในการค้นพบองค์ความรู้ใหม่ ด้วยการเชื่อมโยงกลุ่มของข้อมูลที่เกิดขึ้นในเหตุการณ์เดียวกันไว้ด้วยกัน 5.4. Visualization :เทคนิคที่ใช้ในการแสดงผลในรูปแบบกราฟิกหรือ ข้อมูลหลายมิติ
Classification vs. Prediction predicts categorical class labels classifies data (constructs a model) based on the training set and the values (class labels) in a classifying attribute and ....uses it in classifying new data Prediction: models continuous-valued functions, i.e., predicts unknown or missing values
Classification Process 1. Model construction: 2. Model usage:
Classification Process 1. Model construction: describing a set of predetermined classes Each tuple/sample is assumed to belong to a predefined class, as determined by the class label attribute The set of tuples used for model construction: training set The model is represented as classification rules, decision trees, or mathematical formulae
1. Model Construction Classification Algorithms Training Data Classifier (Model) IF rank = ‘professor’ OR years > 6 THEN tenured = ‘yes’
Classification Process 2. Model usage: for classifying future or unknown objects Estimate accuracy of the model The known label of test sample is compared with the classified result from the model Accuracy rate is the percentage of test set samples that are correctly classified by the model Test set is independent of training set
2. Use the Model in Prediction Classifier Testing Data Unseen Data (Jeff, Professor, 4) Tenured?
What Is Prediction? Prediction is similar to classification 1. Construct a model 2. Use model to predict unknown value Major method for prediction is regression Linear and multiple regression Non-linear regression Prediction is different from classification Classification refers to predict categorical class label Prediction models continuous-valued functions
Data Mining Process Data Preparation Evaluating Classification Methods
1. Data Preparation Data cleaning Preprocess data in order to reduce noise and handle missing values Relevance analysis (feature selection) Remove the irrelevant or redundant attributes Data transformation Generalize and/or normalize data
2. Evaluating Classification Methods Predictive accuracy Speed and scalability time to construct the model time to use the model Robustness handling noise and missing values Scalability efficiency in disk-resident databases Interpretability: understanding and insight proved by the model Goodness of rules decision tree size compactness of classification rules
Supervised vs. Unsupervised Learning Supervised learning (classification) Supervision: The training data (observations, measurements, etc.) are accompanied by labels indicating the class of the observations New data is classified based on the training set Unsupervised learning (clustering) The class labels of training data is unknown Given a set of measurements, observations, etc. with the aim of establishing the existence of classes or clusters in the data
Supervised Learning
Unsupervised Learning
Supervised Data Mining Techniques
Decision Tree
Decision Tree Decision tree A flow-chart-like tree structure Internal node denotes a test on an attribute Branch represents an outcome of the test Leaf nodes represent class labels or class distribution Use of decision tree: Classifying an unknown sample Test the attribute values of the sample against the decision tree
Classification by Decision Tree Decision tree generation consists of two phases 1. Tree construction At start, all the training examples are at the root Partition examples recursively based on selected attributes 2. Tree pruning Identify and remove branches that reflect noise or outliers
Training Dataset This follows an example from Quinlan’s ID3
Output: A Decision Tree for “buys_computer” age? <=30 30..40 overcast >40 student? yes credit rating? no yes excellent fair no yes no yes
Supervised Data Mining Techniques
Supervised Data Mining Techniques
Supervised Data Mining Techniques
What Is Association Mining? Association rule mining: Finding frequent patterns, associations, correlations, or causal structures among sets of items or objects in transaction databases, relational databases, and other information repositories. Applications: Basket data analysis, cross-marketing, catalog design, loss-leader analysis, clustering, classification, etc.
Market Basket Analysis One of the most common uses for data mining Determines what products customers purchase together with other products Results affect how companies Market products Place merchandise in the store Lay out catalogs and order forms Determine what new products to offer Customize solicitation phone calls
Association Rules
Generating Association Rules Confidence and Support -Milk -Cheese -Bread -Eggs Possible associations include the following: 1. If customers purchase milk they also purchase bread. 2. If customers purchase bread they also purchase milk. 3. If customers purchase milk and eggs they also purchase cheese and bread. 4. If customers purchase milk, cheese, and eggs they also purchase bread.
Generating Association Rules Mining Association Rules: An Example
Generating Association Rules Mining Association Rules: An Example
Generating Association Rules Mining Association Rules: An Example
Generating Association Rules Mining Association Rules: An Example Here are three of several possible three-item set rules:
The K-Means Algorithm
The K-Means Algorithm
The K-Means Algorithm General Considerations
The K-Means Algorithm General Considerations
Clustering Techniques
Clustering Techniques
ตัวอย่างการนำเหมืองข้อมูลมาใช้งาน 1. การตลาด ทำนายยอดขายเมื่อมีการลดจำนวนสินค้าลง 2. การเงินการธนาคาร คาดการณ์โอกาสในการชำระหนี้ของลูกค้า 3. การค้าขาย 4. โรงงาน การผลิต 5. ตลาดหลักทรัพย์ 6. ธุรกิจการประกัน 7. H/W S/W คอมพิวเตอร์ 8. กระทรวงกลาโหม 9. โรงพยาบาล
ประโยชน์ของเหมืองข้อมูล 1. ค้นหาข้อมูลโดยอาศัยเทคโนโลยีของเหมืองข้อมูล 2. ใช้สถาปัตยกรรมแบบ Client/Server 3. ผู้ใช้ระบบไม่จำเป็นต้องทักษะในการเขียนโปรแกรม 4. ผู้ใช้ต้องกำหนดขอบเขตและเป้าหมายของระบบให้ชัดเจน เพื่อความรวดเร็วและถูกต้องตามความต้องการ 5. การประมวลผลแบบขนานจะช่วยเพิ่มประสิทธิภาพและความเร็วในการค้นหาข้อมูล
Geographic Information Systems GIS DSS uses geographic databases to construct and display maps and other graphic displays Supports decisions affecting the geographic distribution of people and other resources Often used with Global Positioning Systems (GPS) devices
Dashboard Example
Executive Information Systems EIS Combines many features of MIS and DSS Provide top executives with immediate and easy access to information Identify factors that are critical to accomplishing strategic objectives (critical success factors) So popular that it has been expanded to managers, analysis, and other knowledge workers
Enterprise Information Portals An EIP is a Web-based interface and integration of MIS, DSS, EIS, and other technologies Available to all intranet users and select extranet users Provides access to a variety of internal and external business applications and services Typically tailored or personalized to the user or groups of users Often has a digital dashboard Also called enterprise knowledge portals
Enterprise Information Portal Components
Enterprise Knowledge Portal
It is not enough to stare up the steps... Reference Data Mining: Concepts and Techniques (Chapter 6 Slide for textbook), Jiawei Han and Micheline Kamber, Intelligent Database Systems Research Lab, School of Computing Science, Simon Fraser University, Canada Data Mining A tutorial-Based Primer, Richard J. Roiger and Michael W. Geatz, Pearson Education Inc., 2003 James A. O’Brien and George M. Marakas, Management Information Systems, 8th edition, McGraw-Hill /Irwin, 2008 It is not enough to stare up the steps... We must step up the stairs.
Q & A