ความรู้เบื้องต้นเกี่ยวกับฐานข้อมูล Introduction to Database
ลำดับชั้นของการจัดเก็บข้อมูล
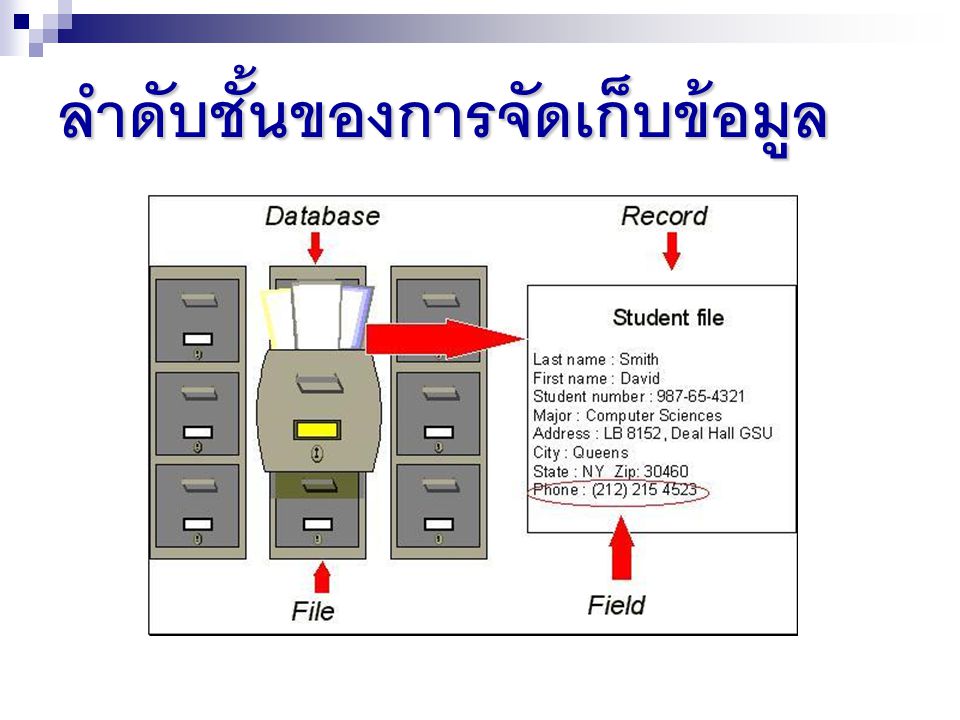
ลำดับชั้นของการจัดเก็บข้อมูล บิต (bit) ย่อมาจาก Binary Digit ข้อมูลในคอมพิวเตอร์ 1 บิต จะแสดงได้ 2 สถานะคือ 0 หรือ 1
ลำดับชั้นของการจัดเก็บข้อมูล ไบต์(byte) คือ นำ บิต หลายๆ บิต มาเรียงต่อกัน จำนวน 8 บิต มาเรียงเป็น 1 ชุด เรียกว่า 1 ไบต์ เช่น 10100001 หมายถึง ก 10100010 หมายถึง ข
ลำดับชั้นของการจัดเก็บข้อมูล เขตข้อมูล(Field) คือ การนำ ไบต์ (byte) หลายๆ ไบต์ มาเรียงต่อกัน เช่น เขตข้อมูล Name ใช้เก็บชื่อ เช่น เขตข้อมูล LastName ใช้เก็บนามสกุล เป็นต้น
ลำดับชั้นของการจัดเก็บข้อมูล ระเบียน(Record) คือ การนำเขตข้อมูล หลายๆ เขตข้อมูล มาเรียงต่อกัน เรียกว่า ระเบียน (record) เช่น ระเบียน ที่ 1 เก็บ ชื่อ นามสกุล วันเดือนปีเกิด ของ นักเรียนคนที่ 1 เป็นต้น
ลำดับชั้นของการจัดเก็บข้อมูล แฟ้มข้อมูล(File) คือ การเก็บระเบียนหลายๆระเบียน รวมกัน เช่น แฟ้มข้อมูล นักเรียน จะเก็บ ชื่อ นามสกุล วันเดือนปีเกิด ของนักเรียน จำนวน 500 คน เป็นต้น
ลำดับชั้นของการจัดเก็บข้อมูล ฐานข้อมูล(Database) คือ การจัดเก็บ แฟ้มข้อมูล หลายๆ แฟ้มข้อมูล ไว้ภายใต้ระบบเดียวกัน เช่น เก็บ แฟ้มข้อมูล นักเรียน อาจารย์ วิชาที่เปิดสอน เป็นต้น
ลำดับชั้นของการจัดเก็บข้อมูล Database Personnel file Department file Payroll file (Project database) Files 098-40-1370 Fiske, Steven 01-05-1985 549-77-1001 Buckley, Bill 02-17-1979 005-10-6321 Johns, Francine 10-07-1997 (Personnel file) Recordประกอบด้วย รหัส , นามสกุลและชื่อ,วันที่จ้างงาน Records 098-40-1370 Fiske, Steven 01-05-1985 Fields Fiske Field นามสกุล Characters (Byte) 1000100 ตัวอักษร F ใน ASCII Bit 0,1
“รูปแบบการจัดเก็บข้อมูลแบบเดิม”
ระบบแฟ้มข้อมูล (File-based System) แฟ้มข้อมูลที่ใช้ในระบบไฟล์จะแยกจากกันเป็นเอกเทศ และอาจไม่มีความสัมพันธ์กัน โดยส่วนใหญ่ข้อมูลและโปรแกรมมักรวมอยู่ด้วยกันเป็นแฟ้มข้อมูล
ระบบแฟ้มข้อมูล (File-based System) โปรแกรมบัญชี การขาย ลูกค้า ฝ่ายบัญชี โปรแกรมการขาย การขาย ลูกค้า สินค้า ฝ่ายขาย โปรแกรมฝ่ายบุคคล พนักงาน ฝ่ายบุคคล
ข้อจำกัดของการประมวลผลแบบแฟ้มข้อมูล ข้อมูลถูกแบ่งและเก็บแยกจากกัน ข้อมูลมีความซ้ำซ้อนกัน มีความขึ้นต่อกันของข้อมูล รูปแบบข้อมูลไม่ตรงกัน โปรแกรมที่ใช้งานมีความคงที่ไม่ยืดหยุ่น
ข้อจำกัดของการประมวลผลแบบแฟ้มข้อมูล ข้อมูลถูกเก็บและเก็บแยกจากกัน เมื่อข้อมูลต่าง ๆ ถูกเก็บกันไว้คนละไฟล์ หากต้องการนำข้อมูลต่าง ๆ มาสร้างเป็นรายงาน โปรแกรมเมอร์ต้องสร้างไฟล์ชั่วคราว(Temporary file)ขึ้นมา เพื่อดึงข้อมูลต่าง ๆ จากไฟล์ต่าง ๆ มารวมกันก่อน แล้วค่อยสร้างเป็นรายงาน
ข้อจำกัดของการประมวลผลแบบแฟ้มข้อมูล ข้อมูลมีความซ้ำซ้อน สืบเนื่องจากข้อมูลถูกเก็บแยกจากกัน ทำให้ไม่สามารถควบคุมความซ้ำซ้อนข้อมูลได้ ทำให้สูญเสียพื้นที่ในการจัดเก็บข้อมูลมากขึ้น และก่อให้เกิดความผิดพลาดในการดำเนินการกับข้อมูล 3 ลักษณะ ได้แก่ ความผิดพลาดจากการเพิ่มข้อมูล(Insertion anomalies) ความผิดพลาดจากการปรับปรุงข้อมูล(Modification anomalies) ความผิดพลาดจากการลบข้อมูล(Deletion anomalies)
ข้อจำกัดของการประมวลผลแบบแฟ้มข้อมูล มีความขึ้นต่อกันของข้อมูล เนื่องจากโครงสร้างทางกายภาพและการจัดเก็บข้อมูลถูกสร้างโดยการเขียนโปรแกรมประยุกต์(Application program) ดังนั้นหากต้องการเปลี่ยนแปลงโครงสร้างข้อมูล เช่น ชื่อของพนักงาน จากเดิม 20 ตัวอักษร เป็น 30 ตัวอักษร มีขั้นตอนการทำงานดังนี้ 1. เปิดไฟล์หลักพนักงานเพื่ออ่านข้อมูล 2. เปิดไฟล์ชั่วคราวที่มีโครงสร้างคล้ายไฟล์หลัก แต่ปรับโครงสร้างของชื่อพนักงาน จาก 20 ตัวอักษร เป็น 30 ตัวอักษร 3. อ่านข้อมูลจากไฟล์หลัก และย้ายไปเก็บไว้ในไฟล์ชั่วคราว จนกระทั่งครบทุกรายการ 4. ลบไฟล์หลักทิ้ง 5. เปลี่ยนชื่อไฟล์ชั่วคราวให้ชื่อเดียวกับไฟล์หลัก
ข้อจำกัดของการประมวลผลแบบแฟ้มข้อมูล รูปแบบข้อมูลไม่ตรงกัน โครงสร้างข้อมูลจะขึ้นอยู่กับภาษาคอมพิวเตอร์ที่ใช้ในการเขียนโปรแกรมประยุกต์ ถ้าแต่ละฝ่ายใช้ภาษาในการเขียนต่าง ๆ กัน ก็อาจทำให้โครงสร้างข้อมูลของแฟ้มไม่ตรงกัน ทำให้ไม่สามารถนำไฟล์ข้อมูลมาใช้ร่วมกันได้
ข้อจำกัดของการประมวลผลแบบแฟ้มข้อมูล โปรแกรมที่ใช้งานคงที่ไม่ยืดหยุ่น ระบบแฟ้มข้อมูล มีความขึ้นกับโปรแกรมประยุกต์ ข้อมูลหรือรายงานต่าง ๆ จะถูกกำหนดรูปแบบตายตัวในโปรแกรมแล้ว ดังนั้นหากต้องการรายงานใหม่ จะต้องให้โปรแกรมเมอร์เขียนโปรแกรมขึ้นมาใหม่ ทำให้เสียค่าใช้จ่าย
“ระบบฐานข้อมูล”
ความหมายของฐานข้อมูล ฐานข้อมูล (Database) หมายถึง โครงสร้างของการจัดเก็บข้อมูลที่มีความสัมพันธ์เกี่ยวข้องกันไว้ในที่เดียวกัน เพื่อให้สามารถนำข้อมูลมาประมวลเพื่อช่วยในการตัดสินใจ และสามารถใช้ข้อมูลร่วมกันได้ ในการจัดการข้อมูลในฐานข้อมูลจะใช้ซอฟต์แวร์ประเภท ระบบจัดการฐานข้อมูล(Database Management System : DBMS)
ฐานข้อมูล(Database) ฐานข้อมูลมีส่วนที่ทำหน้าที่ในการอธิบายความหมายของรายการข้อมูลที่เก็บอยู่ในฐานข้อมูลด้วย เรียกส่วนนี้ว่า บัญชีระบบ(System catalog) หรือ พจนานุกรมของข้อมูล(Data Dictionary) หรือ เมตาดาต้า(Meta - data)1 เมทาดาตา หรือ เมทาเดตา[1] (อังกฤษ: metadata) หมายถึง ข้อมูลที่ใช้กำกับและอธิบายข้อมูลหลักหรือกลุ่มของข้อมูลอื่น ตัวอย่างที่เห็นได้ชัดคือ บัตรในห้องสมุดสำหรับสืบค้นหนังสือ โดยเก็บข้อมูลเกี่ยวกับชื่อหนังสือและตำแหน่งของหนังสือที่ต้องการหา ซึ่งหนังสือเป็นข้อมูลที่ต้องการ และบัตรเป็นข้อมูลที่อธิบายรายละเอียดของข้อมูลนั้น
ฐานข้อมูล(Database) โครงสร้างของข้อมูลจะถูกแยกออกจากโปรแกรมประยุกต์และเก็บเอาไว้ในส่วนที่เรียกว่า “ฐานข้อมูล” ถ้ามีการเพิ่มหรือปรับปรุงโครงสร้างของข้อมูลก็จะไม่มีผลกระทบกับโปรแกรมประยุกต์
ระบบฐานข้อมูล (Database System) โปรแกรมบัญชี ฝ่ายบัญชี ลูกค้า พนักงาน การขาย สินค้า DBMS โปรแกรมการขาย ฝ่ายขาย Database โปรแกรมฝ่ายบุคคล ฝ่ายบุคคล
ระบบแฟ้มข้อมูล (File-based System) โปรแกรมบัญชี การขาย ลูกค้า ฝ่ายบัญชี โปรแกรมการขาย การขาย ลูกค้า สินค้า ฝ่ายขาย โปรแกรมฝ่ายบุคคล พนักงาน ฝ่ายบุคคล
ระบบจัดการฐานข้อมูล (Database Management System : DBMS) หมายถึง ซอฟต์แวร์ที่ใช้ในการจัดการข้อมูลในฐานข้อมูล DBMS จะทำหน้าที่เป็นตัวกลางระหว่างฐานข้อมูลกับโปรแกรมที่มาใช้งานฐานข้อมูลและผู้ใช้งานฐานข้อมูล ที่ติดต่อไปยังฐานข้อมูลเพื่อทำงานที่ผู้ใช้ต้องการให้สำเร็จ เช่น การจัดเก็บข้อมูลลงในฐานข้อมูล , การค้นหาข้อมูลที่ต้องการออกมาแสดง หรือ การลบข้อมูล เป็นต้น
หน้าที่ของ DBMS จัดการพจนานุกรมของข้อมูล(Data dictionary management) จัดการการจัดเก็บข้อมูล(Data storage management) การแปลงข้อมูลและการนำเสนอข้อมูล(Data transformation and presentation) การจัดการด้านความปลอดภัย(Security management) ควบคุมการเข้าใช้งานของผู้ใช้พร้อมกัน(Multiuser accesss control)
หน้าที่ของ DBMS การจัดการเรื่องการสำรองและกู้คืนข้อมูล(Backup and recovery management) การจัดการความคงสภาพของข้อมูล(Data integrity management)1 ภาษาในการเข้าถึงข้อมูลและส่วนประสานผู้ใช้ในโปรแกรมประยุกต์(Database access languages and application programming interfaces) ความคงสภาพ (Integrity) หมายถึง ความถูกต้อง ความมั่นคง และความเป็นอันหนึ่งอันเดียวกัน ดังนั้น ความคง สภาพของข้อมูล จึงหมายความถึง ความถูกต้องของข้อมูลในฐานข้อมูล ฐานข้อมูลเชิงสัมพันธ์มการกําหนด กฎเกณฑ์ของข้อมูลเพือรักษาความถูกต้องของข้อมูลและความสัมพันธ์ระหว่างข้อมูลต่าง ๆ และเป็นการป้องกัน ความเสียหายทีอาจเกิดกับฐานข้อมูล โดยมีจุดประสงค์หลัก คือ (1) ป้องกันความผิดพลาดทีเกิดจากการเพิ่มข้อมูลลงในฐานข้อมูล (2) รักษาความถูกต้องของข้อมูลเมื่อมีการเปลี่ยนแปลงข้อมูลในฐานข้อมูล (3) ระบบจัดการฐานข้อมูลสามารถตัดสินใจได้วา จะจัดการกับข้อมูล ณ ตําแหน่งต่างๆ ในฐานข้อมูลอย่างไร กฎเกณฑ์ในการคงความคงสภาพของข้อมูลสามารถแบ่งได้ 3 ประเภท ได้แก่ 1. กฏเกณฑ์เกียวกับชนิ ดของข้อมูล (Type constraint) ข้อมูลแต่ละชนิดในฐานข้อมูลมีลกษณะการเก็บในฐานข้อมูลและการนํ าไปใช้งานต่างกัน เพือให้ขอมูลเหล่านีมีความถูกต้องก่อนการนํ าไปใช้งานจึงต้องมีการตรวจสอบชนิดและค่าของข้อมูลชนิดนันว่าถูกต้องหรือไม่ 2. กฏเกณฑ์เกียวกับฟิ ลด์ของข้อมูล (Attribute constraint) กฎเกณฑ์ทใช้ในการกําหนดความถูกต้องของฟิ ลด์ขอมูลสามารถแยกได้ 3 ประเภท ตามชนิดของแอท ทริบว คือ (1) ความคงสภาพของคีย์ (Key integrity) - การทีค่าของคีย์จะต้องเป็นค่าทีมีเอกลักษณ์ ไม่ซํากับข้อมูลใดในแถวอืน (2) ความคงสภาพของเอ็นทิตี (Entity integrity) - การทีค่าของฟิ ลด์ทเป็นคีย์หลักไม่สามารถเป็นค่าว่างได้ (3) ความคงสภาพของการอ้างอิงฟิ ลด์ (Referential integrity) - การอ้างอิงถึงฟิ ลด์จากความสัมพันธ์ หนึงในความสัมพันธ์ใด จะต้องเป็นการอ้างอิงถึงฟิ ลด์ทมีอยู่จริงในความสัมพันธ์นน การอ้างอิงถึงฟิ ลด์ทไม่มอยู่ จริงจะทําให้ไม่สามารถรักษาความคงสภาพของข้อมูลไว้ได้ 3. กฎเกณฑ์เกียวกับฐานข้อมูล (Database constraint) การประมวลผลทีเกิดขึนภายในฐานข้อมูล อันได้แก่ การอ่านข้อมูลและการเขียนข้อมูล มีผลโดยตรงต่อ ความคงสภาพของข้อมูล ผลลัพธ์จากการทํางานบางอย่างของฐานข้อมูลจะทําให้เกิดความเสียหายกับข้อมูลได้ หรืออาจจะทําให้ระบบล้ม ซึงจะมีผลให้ฐานข้อมูลอยู่ในสถานะทีไม่มนคง (Unconsistency) ดังนันระบบจัดการ ฐานข้อมูลจึงจําเป็นต้องรักษากฏเกณฑ์ทเกียวกับการทํางานในฐานข้อมูลเอาไว้ เพือป้องกันความเสียหายทีอาจจะเกิดขึนได้เหล่านี
การประยุกต์ใช้ระบบงานฐานข้อมูล การซื้อของจากซูเปอร์มาเก็ต การซื้อของโดยใช้บัตรเครดิต การจองตั๋วเครื่องบินผ่านตัวแทนจำหน่าย การใช้บริการห้องสมุด การใช้งานอินเทอร์เน็ต การเรียนในมหาวิทยาลัย การบริหารในองค์กร ฯลฯ อีกมากมาย
องค์ประกอบของระบบฐานข้อมูล ฮาร์ดแวร์ Hardware ซอฟต์แวร์ Software ข้อมูล Data กระบวนการ Procedure บุคลากร People เครื่อง มนุษย์ สะพาน
ฮาร์ดแวร์(Hardware) หมายถึงคอมพิวเตอร์และอุปกรณ์รอบข้างซึ่งเกี่ยวข้องกับการใช้งานฐานข้อมูล
ซอฟต์แวร์(Software) หมายถึง ระบบปฏิบัติการ , ระบบจัดการฐานข้อมูล , โปรแกรมประยุกต์ และโปรแกรมยูทิลิตี้ต่าง ๆ ที่เกี่ยวข้องกับการใช้งานในระบบงานฐานข้อมูล
ข้อมูล(Data) หมายถึง ข้อมูลที่จัดเก็บอยู่ในฐานข้อมูล เพื่อนำไปใช้ในการประมวลต่อไป ใน DBMS จะส่วนที่ใช้อธิบายข้อมูล ซึ่งจะเป็นข้อมูลที่บรรยายคุณลักษณะของข้อมูล(meta data)
โพรซีเยอร์(Procedure) หมายถึง คำสั่งและกฎต่าง ๆ ในขั้นตอนการปฏิบัติงานที่เกี่ยวข้องกับชุดคำสั่ง กฏเกณฑ์ในการออกแบบและการใช้งานฐานข้อมูล
บุคลากร(People) หมายถึงบุคคลที่เกี่ยวข้องกับระบบงานฐานข้อมูล ทั้งส่วนที่เป็นการออกแบบและการใช้งาน เช่น ผู้ใช้ทั่วไป , นักออกแบบฐานข้อมูล , นักออกแบบระบบ
ผู้ที่มีส่วนเกี่ยวข้องกับการใช้งานฐานข้อมูล ผู้บริหารฐานข้อมูล(Database Administrator :DBA) นักออกแบบฐานข้อมูล(Database Designer) นักพัฒนาโปรแกรม(Application Developers) ผู้ใช้(End User)
ข้อดีของการใช้งานฐานข้อมูล มีความเป็นอิสระต่อกันระหว่างโปรแกรมและข้อมูล ลดความซ้ำซ้อนของข้อมูล เพิ่มความตรงกันของข้อมูล สามารถใช้ข้อมูลร่วมกันได้ บังคับให้เป็นมาตรฐานเดียวกันได้ ป้องกันและควบคุมการเข้าถึงข้อมูลได้ง่ายขึ้น ลดปัญหาในการบำรุงรักษาโปรแกรม
ข้อจำกัดของระบบการจัดการฐานข้อมูล ซับซ้อน(Complexity) ขนาดใหญ่(Size) ราคาของDBMSแพง(Cost of DBMS) ราคาของฮาร์ดแวร์แพงตามไปด้วย(Additional hardware cost) ค่าใช้จ่ายในการแปลงระบบ(Cost of conversion) ผลกระทบจากความเสียหายสูง(Higher impact of a failure)
ชนิดของระบบฐานข้อมูล ในการจำแนกชนิดของระบบฐานข้อมูลมีเกณฑ์ในการแบ่งเป็น 2 ชนิดคือ แบ่งตามลักษณะการใช้งาน แบ่งตามสถานที่ตั้ง
ชนิดของฐานข้อมูล:ลักษณะการใช้งาน ฐานข้อมูลที่มีผู้ใช้คนเดียว(Single-User) บางครั้งเรียกว่า Stand alone database หรือ Desktop database
ชนิดของฐานข้อมูล:ลักษณะการใช้งาน ฐานข้อมูลที่มีผู้ใช้ครั้งละหลายคน(Multi-User) ระบบฐานข้อมูลแบบนี้จะสนับสนุนการใช้งานของผู้ใช้หลายคนในเวลาเดียวกัน
ชนิดของฐานข้อมูล : สถานที่ตั้งของฐานข้อมูล ฐานข้อมูลแบบรวมศูนย์(Centralized Database System) Client Server Client Client Client
ระบบฐานข้อมูลแบบรวมศูนย์ (Centralized Database System) ประกอบด้วย ฐานข้อมูลซอฟต์แวร์จัดการฐานข้อมูล และหน่วยความจำที่ใช้ในการจัดเก็บฐานข้อมูล ซึ่งอาจจะเป็นจานบันทึก (Disk) สำหรับการจัดเก็บแบบเชื่อมตรง (on-line) หรืออาจจะเป็นแถบบันทึก (Tape) สำหรับการจัดเก็บแบบไม่เชื่อมตรง (off-line) เพื่อใช้เป็นหน่วยเก็บสำรอง ระบบฐานข้อมูลแบบนี้สามารถถูกเรียกใช้งานได้จากจุดอื่นๆ ที่มีเครื่องปลายทาง (Terminal) ประจำอยู่ แต่ละฐานข้อมูลและ ซอฟต์แวร์จะอยู่รวมกันที่จุดเดียวเท่านั้น ซึ่งเมื่อ ระบบคอมพิวเตอร์เจริญมากขึ้น พร้อมทั้งพัฒนาการในเรื่องเครือข่ายสำหรับการติดต่อดีมากขึ้น ทำให้มีการศึกษาและพัฒนาระบบฐานข้อมูลแบบกระจายขึ้น
ชนิดของฐานข้อมูล : สถานที่ตั้งของฐานข้อมูล ฐานข้อมูลแบบกระจาย(Distributed Database System)
เหตุผลในการใช้ฐานข้อมูลแบบกระจาย 1. ความสามารถในการดึงข้อมูล งานฐานข้อมูลบางอย่างมีข้อมูลกระจัดกระจายอยู่ตามแหล่งต่างๆ หน่วยงานบางแห่งอาจจะมีสาขาอยู่ตามจังหวัด ตัวอย่างเช่น ธนาคารจะมีสาขาอยู่ทั่วประเทศ ข้อมูลของแต่ละสาขาก็จะถูกเก็บไว้ที่สาขานั้นๆ แต่ในบางครั้งผู้บริหาร หน่วยงานที่ส่วนกลางอาจต้องการข้อมูลสรุป ซึ่งต้องใช้ข้อมูลจากหลายๆ สาขาทั่วประเทศ ซึ่งในกรณีนี้ ระบบจัดการฐานข้อมูลควรจะมีความสามารถในการดึงข้อมูลจากสาขาต่างๆ ได้ด้วย 2. เพิ่มความน่าเชื่อถือและความทันสมัยของข้อมูล เพิ่มความน่าเชื่อถือและความทันสมัยของข้อมูล สำหรับข้อมูลที่กระจายอยู่ตามจุดต่าง ๆ เมื่อมีการเปลี่ยนแปลงค่าของข้อมูล ณ จุดนั้นข้อมูลใหม่จะถูกบันทึกแทนข้อมูลเก่าทันที และสามารถนำมาใช้งานได้ ณ เวลานั้น เนื่องจาก ซอฟต์แวร์สำหรับจัดการฐานข้อมูลกระจายอยู่ตามจุดต่างๆ นอกจากนี้ ถ้าระบบในบางจุดย่อยเสียหายและไม่สามารถทำงานได้ ระบบ ณ จุดอื่นๆ ก็ยังคงสามารถทำงานต่อไปได้ แต่ถ้าเป็นแบบ
เหตุผลในการใช้ฐานข้อมูลแบบกระจาย 3. เพื่อควบคุมการเข้าใช้ข้อมูล เพื่อควบคุมการเข้าใช้ข้อมูล ทั้งนี้เนื่องจากข้อมูลกระจัดกระจายอยู่ตามจุดต่างๆ ทำให้ผู้ดูแลระบบสามารถกำหนดได้ว่า ผู้ใช้จากจุดใดสามารถเข้าใช้ข้อมูลจากจุดใดได้บ้าง และได้มากระดับใดด้วย 4. เพิ่มประสิทธิภาพการทำงาน เพิ่มประสิทธิภาพการทำงาน เมื่อมีการกระจายข้อมูลตามจุดต่างๆ จะส่งผลให้ฐานข้อมูลย่อยแต่ละจุดมีขนาดเล็กลง ซึ่งทำให้เมื่อมีการสอบถามข้อมูลในแต่ละฐานข้อมูลย่อย การค้นหาข้อมูลย่อมทำได้รวดเร็วขึ้น นอกจากนี้ ผู้ใช้ก็กระจายอยู่ตามจุดต่างๆ แต่ละจุด จึงสามารถทำงานขนานกันได้เลย ซึ่งไม่เหมือนกับระบบรวมศูนย์ที่จะต้องส่งทุกๆ คำสั่งไปที่เดียวกันหมด และทำให้ต้องรอลำดับในการทำงาน เพราะไม่สามารถทำงานพร้อม ๆ กันได้