ดาวน์โหลดงานนำเสนอ
งานนำเสนอกำลังจะดาวน์โหลด โปรดรอ

1
การวิเคราะห์กลุ่ม (Cluster Analysis)
โดย นางสาวจิตรลดา ทองอันตัง นายสุขสมพร อโนไท

2
1.ความหมายของ Cluster Analysis
เป็นเทคนิคที่ใช้จำแนกหรือจัด Case (หมายถึง คน สัตว์ สิ่งของ หรือ องค์กร ฯลฯ) หรือจัดตัวแปรออกเป็นกลุ่มย่อย ๆ ตั้งแต่ 2 กลุ่มขึ้นไป Case ที่อยู่ในกลุ่มเดียวกันจะมีลักษณะที่เหมือนกันหรือคล้ายกัน ส่วน Case ที่อยู่ต่างกลุ่มกันจะมีลักษณะที่แตกต่างกัน - ตัวแปรอยู่ในกลุ่มเดียวกันมีความสัมพันธ์กันมากกว่าตัวแปรที่อยู่ต่างกลุ่มกัน ตัวแปรที่อยู่ต่างกลุ่มกันมีความสัมพันธ์กันน้อยหรือไม่มีความสัมพันธ์กันเลย
 หรือจัดตัวแปรออกเป็นกลุ่มย่อย ๆ ตั้งแต่ 2 กลุ่มขึ้นไป Case ที่อยู่ในกลุ่มเดียวกันจะมีลักษณะที่เหมือนกันหรือคล้ายกัน ส่วน Case ที่อยู่ต่างกลุ่มกันจะมีลักษณะที่แตกต่างกัน. - ตัวแปรอยู่ในกลุ่มเดียวกันมีความสัมพันธ์กันมากกว่าตัวแปรที่อยู่ต่างกลุ่มกัน ตัวแปรที่อยู่ต่างกลุ่มกันมีความสัมพันธ์กันน้อยหรือไม่มีความสัมพันธ์กันเลย.")
3
Cluster Analysis จัดกลุ่มโดยพยายามให้สิ่งที่อยู่ในกลุ่มเดียวกันมีความคล้ายคลึงกันมากที่สุด (Minimize Intra-Cluster Distances) และพยายามให้แต่ละกลุ่มมีความแตกต่างกันมากที่สุด (Maximize Inter-Cluster Distances) Inter-cluster distances are maximized Intra-cluster distances are minimized
 และพยายามให้แต่ละกลุ่มมีความแตกต่างกันมากที่สุด (Maximize Inter-Cluster Distances) Inter-cluster distances are maximized. Intra-cluster distances are minimized.")
4
Cluster Analysis การวิเคราะห์เพื่อศึกษาว่าบุคคล (Cases) หรือสิ่งต่างๆ (Objects) จะสามารถนำมาจัดกลุ่มกันตามความเหมือน (Similarity) หรือความแตกต่าง (Dissimilarity or Distance) ของตัวแปร (Variables) ได้กี่กลุ่ม อย่างไรบ้าง บุคคลหรือสิ่งที่มีความคล้ายคลึงกันในตัวแปรที่นำมาวิเคราะห์จะถูกจัดอยู่ในกลุ่ม (Cluster) เดียวกัน ส่วนบุคคลหรือสิ่งที่แตกต่างกันในตัวแปรจะถูกจัดอยู่คนละกลุ่มกัน 4
 หรือสิ่งต่างๆ (Objects) จะสามารถนำมาจัดกลุ่มกันตามความเหมือน (Similarity) หรือความแตกต่าง (Dissimilarity or Distance) ของตัวแปร (Variables) ได้กี่กลุ่ม อย่างไรบ้าง. บุคคลหรือสิ่งที่มีความคล้ายคลึงกันในตัวแปรที่นำมาวิเคราะห์จะถูกจัดอยู่ในกลุ่ม (Cluster) เดียวกัน ส่วนบุคคลหรือสิ่งที่แตกต่างกันในตัวแปรจะถูกจัดอยู่คนละกลุ่มกัน. 4.")
5
2.ข้อสมมติหรือเงื่อนไขเทคนิดการวิเคราะห์กลุ่ม
ไม่ทราบจำนวนกลุ่มมาก่อนว่ามีกี่กลุ่ม ไม่ทราบมาก่อนว่าหน่วยไหนหรือคนใดจะอยู่กลุ่มใด หน่วยหรือคนใดคนหนึ่งจะต้องอยู่กลุ่มใดกลุ่มหนึ่งเพียงกลุ่มเดียว ตัวแปรที่ใช้ในการแบ่งกลุ่มมีมากกว่า 1 ตัว และตัวแปรอาจเป็นตัวแปรตัวแปรที่มีค่าได้เพียง 2 ค่า หรือเป็นตัวแปรเชิงคุณภาพ หรือตัวแปรเป็นปริมาณ

6
3. วัตถุประสงค์ของ Cluster Analysis
เพื่อจัดกลุ่ม Case ซึ่งจะเป็นประโยชน์ในงานด้านต่าง ๆ เช่นการตลาด การแพทย์ การปกครอง ฯลฯ ดังตัวอย่างต่อไปนี้ 6

7
ตัวอย่างที่ 1 ใช้ศึกษาพฤติกรรมการบริโภคของกลุ่มผู้บริโภคที่อยู่ต่างกลุ่มกัน ซึ่งจะทำให้สามารถวางกลยุทธ์ทางการตลาดได้อย่างมีประสิทธิภาพมากขื้น การที่จะสามารถแยกกลุ่มผู้บริโภคเป็นกลุ่มย่อยได้ จะต้องพิจารณาถึงตัวแปรที่ใช้ในการแบ่งกลุ่มผู้บิริโภค ที่จะทำให้ผู้ที่อยู่ต่างกลุ่มกันมีพฤติกรรมการบริโภคที่แตกต่างกัน ตัวแปรดั่งกล่าวอาจประกอบด้วย อาชีพ อายุ รายได้ เป็นต้น 4/5/2017

8
ตัวอย่างที่ 2 การเปรียบเทียบรถยนต์ยี่ห้อต่างๆ โดยที่ 1 Case คือรถยนต์ 1 ยี่ห้อซึ่งพิจารณาจากตัวแปร เช่น ความถี่ในการซ่อม ลูกสูบ ระบบแบรก ค่าใช้จ่ายต่อกิโลเมตรราคาเป็นต้น

9
ข้อสังเกต จากตัวอย่างที่ 1 ข้างต้น จะพบว่าการเลือกตัวแปรเพื่อนำมาใช้จัดกลุ่ม Case มีความสำคัญมาก เพราะถ้าผู้วิจัยเลือกตัวแปรที่ไม่ได้ทำ Case แตกต่างกันแล้ว จะทำให้ไม่สามารถจัดกลุ่มได้ถูกต้อง การเลือกจะต้องพิจารณาว่าตัวแปรใดบ้างที่มีอิทธิพลทำให้เกิดความแตกต่าง นอกจากนั้น การจัดกลุ่มตัวแปรทำให้ทราบว่าตัวแปรใดบ้างที่มีความสัมพันธ์กัน การเปลี่ยนแปลงของตัวแปรบางตัวย่อมมีผลกระทบต่อตัวแปรอื่น ๆ ที่มีความสัมพันธ์กับตัวแปรดังกล่าว

10
4.การวัดความคล้าย (Similarity Measure)
ดังที่ได้กล่าวมาแล้วถึงหลักเกณฑ์ของเทคนิค Cluster ว่าจะใช้ในการจัด Case ที่คล้ายกันไว้ในกลุ่มเดียวกัน หรือจัดกลุ่มตัวแปรที่สัมพันธ์กันไว้ในกลุ่มเดียวกัน นั่นคือ จะมีความวัดคล้ายกันของ Case ที่ละคู่ ในกรณีที่เป็นการจัดกลุ่ม Case ส่วนการจัดกลุ่มตัวแปร การวัดความคล้ายจะเป็นการวัดความคล้ายของตัวแปรแต่ละคู่ คือการหาค่าสัมประสิทธิ์สหสัมพันธ์ เมื่อต้องการจัดกลุ่ม Case

11
4.1 การวัดค่าความต่าง ของหน่วย 2 หน่วย เช่น คน 2 คน หรือ 2 องค์กร เป็นการหาระยะห่าง ระหว่าง 2 หน่วย เช่นการศึกษา ความต่างของคน 2 คน (นาย ก และ นาย ข) ในด้านรายได้รายจ่าย ถ้านาย ก และนาย ข มีความต่างกันน้อย หรือระยะห่างต่างกันน้อย หรือถ้าระยะห่าง ก และ ข มีรายได้ไกล้ศูนย์ แสดงว่า ก และ ข อยู่ใกล้กัน หรือค้ายกัน จึ่งควรให้นาย ก และ นาย ข อยู่ในกลุ่มเดียวกัน แต่ถ้านาย ก และ นาย จ มีความต่างกันมากหรืออยู่ห่างกันมากจึ่งมีรยะห่างมาก ก็จะจัดให้นาย ก และนาย จ อยู่คนละลุ่ม 4/5/2017

12
ระยะห่างยุดลิดกำลังสอง (Euclidean Distance)
4/5/2017

13
ตัวอย่าง 3 การศึกษาความแตกต่างของอายุและรายได้ของนายสาวจอย และนางสาวพลอยได้ข้อมูลดังนี้
อายุ (ปี) รายได้(บาท) จอย 20 7,200 พลอย 40 7,500 ค่าเฉลี่ย 30 7,350 ค่าเบี่ยงเบนมาตรฐาน ข้อมูลดิบ การวัดความต่างของนางสาวจอย และนางสาวพลอย ในที่นี้จะใช้ระยะห่างยุคลิดกำลังสอง ระยะห่าง= =400+90,000=90,400
 รายได้(บาท) จอย ,200. พลอย ,500. ค่าเฉลี่ย ,350. ค่าเบี่ยงเบนมาตรฐาน. ข้อมูลดิบ. การวัดความต่างของนางสาวจอย และนางสาวพลอย ในที่นี้จะใช้ระยะห่างยุคลิดกำลังสอง. ระยะห่าง= =400+90,000=90,400.")
14
ค่าเบี่ยงเบนมาตรฐาน

15
ค่ามาตฐานของข้อมูล อายุ รายได้ จอย พลอย

16
4/5/2017

17
ระยะห่างของจอย และพลอย =
ซึ่งเป็นผลจากอายุและรายได้เท่ากัน คือร้อยละ 50 ดังนั้นก่อนใช้เทคนิคการวิเคราะกลุ่มควรปรับหรือจำกัดหน่วยของตัวแปรที่แตกต่างกันออกไป ดังในตัวอย่างนี้ปรับให้เป็นค่ามาตรฐานที่ไม่มีหน่วย 4/5/2017

18
4.3 การคำนวณระยะห่างและความคล้ายของข้อมูลที่มีค่าได้เพียงสองค่า (Binary data)
การวัดความคล้ายและความต่างของ 2 หน่วย หรือ 2 คนจะต้องสร้างตารางขนาด 2 2 เพื่อศึกษาความคล้าย หรือความต่าง การสร้างความคล้ายหรือความต่างของนาย วิน และ กัน พิจรณาดังนี้ ตัวอย่าง 4 การวัดความสามารถด้านภาษา ถ้าพูดภาษาอังกฤได้จะได้หมายเลข 1 ถ้าพูดไม่ได้หมายเลข 0 ตัวอย่าง เช่นถ้ามีตัวแปร 4 ตัว (X1, X2 , X3 , X4) 4/5/2017
 4/5/2017.")
19
X1 X2 X3 X4 วิน 1 กัน จากตารางจะพบว่า วิน และ กัน คล้ายกันใน X2 และ X แต่ต่างกัน X1 และ X4 4/5/2017

20
เช่น X A1= นายกัน รวม 1 นาย วิน 2 4 4/5/2017

21
หน่วยที j รวม 1 หน่วยที i a b a+b c d C+d a+c b+d a+b+c+d
ในรูปทั่วไปกรณีที่มีตัวแปร p (X1, X2 ,… Xp) ตารางความถี่เพื่อเปรียบเทียบความคล้าย และความต่างของที่ i และ j จะเป็น หน่วยที j รวม 1 หน่วยที i a b a+b c d C+d a+c b+d a+b+c+d 4/5/2017
 ตารางความถี่เพื่อเปรียบเทียบความคล้าย และความต่างของที่ i และ j จะเป็น. หน่วยที j. รวม. 1. หน่วยที i. a. b. a+b. c. d. C+d. a+c. b+d. a+b+c+d. 4/5/2017.")
22
4.4 การวัดความต่าง 2. ระยะห่างยุคลิด (Euclidean Distance)
4.4 การวัดความต่าง 1. ระยะห่างยุคลิดกำลังสอง (Square Euclidean Distance) 2. ระยะห่างยุคลิด (Euclidean Distance) 4/5/2017
 2. ระยะห่างยุคลิด (Euclidean Distance) 4/5/2017.")
23
4.5 การวัดความคล้าย Simple Matching เป็นการให้หนักเท่ากันกับลักษณะที่เหมือนกัน

24
ตัวอย่าง 5 จากการตอบถามความคิดเห็นด้วยคำถาม 6 คำถามต่อสามีภรรยา 1 คู่โดยคำถามเป็นดั่งนี้
x1 x2 x3 x4 x5 x6 สามี 1 ภรรยา

25
นำข้อมูลมาสร้างตารางความถี่จำแนก 2 ทาง
ภรรยา สามี รวม 1 (เห็นด้วย) 0 (ไม่เห็นด้วย) 3 1 2 4 P=6
 0 (ไม่เห็นด้วย) P=6.")
26
5. ประเภทของเทคนิค Cluster Analysis
Hierarchical Cluster Analysis K-Means Cluster Analysis

27
5.1 เทคนิค Hierarchical Cluster Analysis
เป็นเทคนิคที่ใช้กันมากในการแบ่งกลุ่ม Case หรือแบ่งกลุ่มตัวแปรโดยมีเงื่อนไขดังต่อไปนี้ 1. ในกรณีที่ใช้การแบ่ง Case นั้น จำนวน Case ไม่ต้องมากนัก (จำนวน Case ควรต่ำกว่า 200 ถ้าตั้ง 200 ขื้นไปใช้ K-Means Cluster ) และจำนวนตัวแปรไม่ต้องมากเช่นกัน 2. ไม่จำเป้นต้องทราบจำนวนกลุ่มาก่อน 3. ไม่จำเป็นต้องทราบว่าตัวแปรใด หรือ Case ใดอยู่กลุ่มใดมาก่อน 4/5/2017
 และจำนวนตัวแปรไม่ต้องมากเช่นกัน. 2. ไม่จำเป้นต้องทราบจำนวนกลุ่มาก่อน. 3. ไม่จำเป็นต้องทราบว่าตัวแปรใด หรือ Case ใดอยู่กลุ่มใดมาก่อน. 4/5/2017.")
28
6. การวิเคราะห์กลุ่มแบบขั้นตอน (Hierarchical Cluster Aalysis)
4/5/2017

29
6.1 เทคนิค Hierarchical Cluster Analysis
แบ่งเป็น 2 เทคนิคย่อยคือ 1. Agglomerative Hierarchical Cluster Analysis 2. Divisive Hierarchical Cluster Analysis สำหรับโปรแกรมสำเร็จรูปทั่วไป จะใช้เทคนิค Agglomerative Hierarchical Cluster Analysis

30
6.1.1 Agglomerative HierarchicalCluster Analysis
เริ่มต้นจะสมมติว่ามี n กลุ่มย่อย สิ่งของ หรือ item ที่มีระยะสั้นที่สุด หรือคล้ายกันมากที่สุดจะรวมเข้าด้วยกันเป็นกลุ่มก่อน จึงเหลือ n-1 กลุ่มย่อย จากนั้นหาระยะทางหรือความคล้ายจาก n – 1 กลุ่มย่อยใหม่ แล้วดูว่ากลุ่มย่อยใดมีระยะทางสั้นที่สุด หรือคล้ายกันมากที่สุดก็รวมกลุ่มย่อยนั้นเข้าด้วยกัน ทำเช่นนี้ต่อ ๆ ไป ในท้ายที่สุดแล้วจะมีเพียง 1 กลุ่มซึ่งประกอบด้วยสิ่งของ n สิ่ง

31
ข้อจำกัดของวิธี Agglomerative Hierarchical Cluster Analysis
เนื่องจากวิธี Agglomerative Hierarchical Cluster Analysis จะเริ่มต้นให้จำนวน case = จำนวน cluster เช่น มี n case = มี n cluster แล้วค่อย ๆ ลดจำนวน cluster ทีละ 1 โดยรวมกลุ่ม 2 cluster ที่คล้ายกันมากที่สุด หรือต่างกันน้อยที่สุดเข้าด้วยกัน จึงค่อยๆ ลดจำนวน cluster ครั้งละ 1 ดังนั้น ถ้ามี n มาก เช่น n = 1,000 คน จะต้องทำการรวมกลุ่ม ครั้งโดยเริ่มจากมี 1,000 cluster แล้วลดเหลือ cluster , cluster เป็นเช่นนี้ไปเรื่อย ๆ จนเหลือ 1 cluster ซึ่งจะทำให้เสียเวลามาก ดังนั้นโดยทั่วไปถ้ามีจำนวน case มากว่า case จึงไม่นิยมใช้เทคนิค Hierarchical Cluster

32
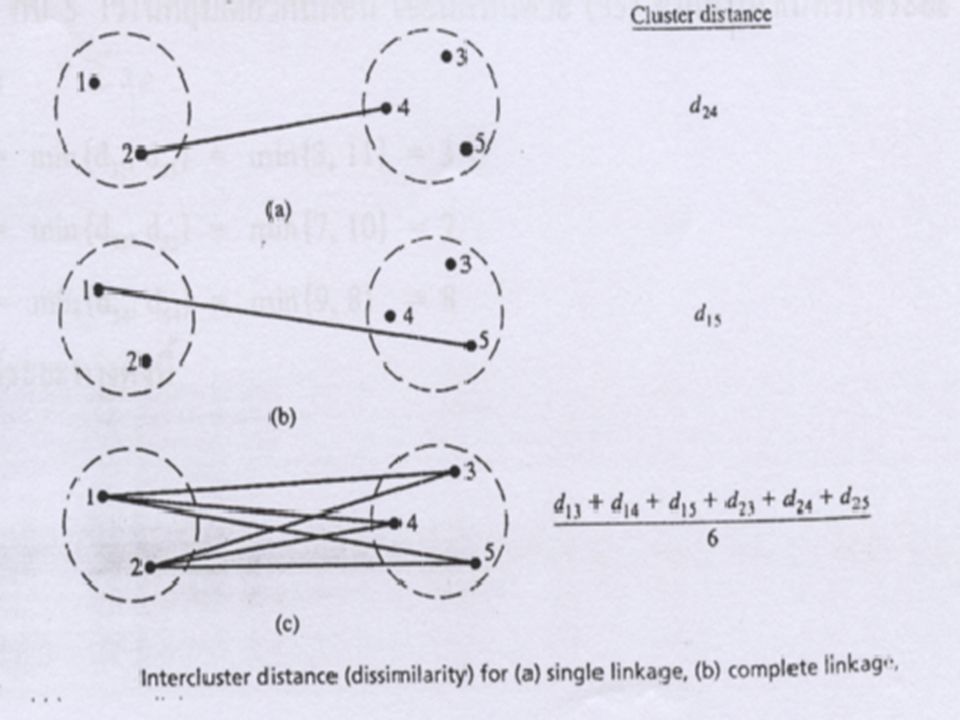
ใน Agglomerative Hierarchical Cluster Analysis จะมีวิธีที่เรียกว่า Linkage method ที่เป็นที่รู้จักกันโดยทั่วไปมี 3 วิธีคือ 1. single linkage (หรือเรียกว่า nearest neighbor) 2. complete linkage (หรือ furthest neighbor) 3. average linkage (หรือ average distance) แนวคิดทั้ง 3 วิธีอธิบายด้วยรูปดังนี้
 2. complete linkage (หรือ furthest neighbor) 3. average linkage (หรือ average distance) แนวคิดทั้ง 3 วิธีอธิบายด้วยรูปดังนี้")
34
ชนิดของข้อมูลหรือตัวแปรที่สามารถใช้
เทคนิค Hierarchical Cluster ได้ มี 3 ประเภท คือ 1. ข้อมูลเป็นสเกลอันตรภาค (Interval scale) หรือสเกล อัตราส่วน (Ratio scale) 2. ข้อมูลที่อยู่ในรูปความถี่ (Count Data) 3. ข้อมูลอยู่ในรูป Binary นั่นคือ มีได้ 2 ค่า คือ 0 กับ 1 หรือ คุณภาพ
 หรือสเกล อัตราส่วน (Ratio scale) 2. ข้อมูลที่อยู่ในรูปความถี่ (Count Data) 3. ข้อมูลอยู่ในรูป Binary นั่นคือ มีได้ 2 ค่า คือ 0 กับ 1 หรือ คุณภาพ.")
35
กรณีที่วัดความคล้ายด้วยระยะห่าง
ถ้าระยะห่างระหว่าง Case คู่ใดต่ำ แสดงว่า Case คู่นั้นอยู่ใกล้กัน หรือมีความคล้ายกัน ควรจะจัดให้อยู่ในกลุ่ม หรือ Cluster เดียวกัน สำหรับวิธีการคำนวณจะขึ้นอยู่กับชนิดของข้อมูลทั้ง 3 ชนิดข้างต้น (Interval scale , Count Data , Binary )
")
36
กรณีที่วัดความคล้ายด้วยของ Case
ถ้าค่าความคล้ายของ Case คู่ใดมีค่ามากแสดงว่า Case คู่นั้นคล้ายกันมาก จึงควรจัดให้อยู่ในกลุ่มเดียวกัน การคำนวณค่าความคล้ายจะแตกต่างกัน ถ้าชนิดของข้อมูลแตกต่างกัน

37
กรณีที่วัดความคล้ายของตัวแปรด้วยค่าสัมประสิทธิ์สหสัมพันธ์
ถ้าตัวแปรคู่ใด มีค่าสัมประสิทธิ์สหสัมพันธ์มาก แสดงว่าคู่นั้นสัมพันธ์กันมากควรจัดไว้ในกลุ่มเดียวกัน

38
หลักเกณฑ์ในการรวมกลุ่ม
1. Between – groups Linkage หรือเรียกว่าวิธี Average Linkage Between Groups หรือเรียกกว่า UPGMA (Unweightede Pair-Group Method Using Arithmetic Average)
")
39
วิธีนี้จะคำนวณหาระยะห่างเฉลี่ยของทุกคู่ของ Case โดยที่ Case หนึ่งอยู่ใน Cluster ที่ i ส่วนอีก Case หนึ่งอยู่ใน Cluster ที่ j ถ้า Cluster ที่ i มีระยะห่างเฉลี่ยจาก Cluster ที่ j สั้นกว่าระยะห่างจาก Cluster อื่นจะนำ Cluster ที่ i และ j รวมกันเป็น Cluster เดียวกัน

40
2. Within-group Linkage Technique
วิธีนี้จะรวม Cluster เข้าด้วยกัน ถ้าระยะห่างเฉลี่ยระหว่างทุก Case ใน Cluster นั้น ๆ มีค่าน้อยที่สุด

41
3. Nearest Neighbor หรือเรียกว่า Single Linkage
วิธีนี้จะรวม Cluster 2 Cluster เข้าด้วยกันโดยพิจารณาจากระยะห่างที่สั้นที่สุด โดยที่ dik เป็นระยะห่างที่สั้นที่สุดระหว่าง Cluster i และ k ในรูปจะรวม Cluster i และ j เข้าด้วยกันเพราะ dij < dik

42
4. Furthest Neighbor Technique หรือเรียกว่า Complete Linkage
วิธีนี้จะรวม Cluster 2 Cluster เข้าด้วยกันโดยพิจารณาจากระยะห่างที่ยาวที่สุด dik = ระยะห่างที่ยาวที่สุดของ Cluster ที่ i และ k dij = ระยะห่างที่ยาวที่สุดของ Cluste ที่ i และ j ในที่นี้ dij < dik จึงรวม Cluster ที่ i และ j เข้าเป็น Cluster เดียวกัน

43
5. Centroid Clustering วิธีการนี้จะคำนวณหาระยะห่างระหว่าง Centroid ของ Cluster ทีละคู่ ในที่นี้จะเรียกค่าเฉลี่ย หรือค่ากลางของแต่ละ Cluster ว่า Centroid ของ Cluster เนื่องจากการจัดกลุ่มCase จะพิจารณาจากตัวแปรหลาย ๆ ตัวพร้อม ๆ กัน จึงเรียกค่ากลางหรือค่าเฉลี่ยว่า Centroid ถ้าระยะห่างระหว่าง Centroid ของ Cluster คู่ใดต่ำจะรวม Cluster คู่นั้นเข้าเป็น Cluster เดียวกัน

44
6. Median Clustering วิธีนี้จะรวม Cluster 2 Cluster เข้าด้วยกัน โดยให้แต่ละ Cluster สำคัญเท่ากัน (ให้น้ำหนักเท่ากัน) ในขณะที่วิธีของ Centroid Clustering จะให้ความสำคัญแก่ Cluster มีขนาดใหญ่มากกว่า Cluster ที่มีขนาดเล็ก (ให้น้ำหนักไม่เท่ากัน) Median Clustering จะใช้ค่า Median เป็นค่ากลางของ Centroid ถ้าระยะห่าง ระหว่างค่า Median ของ Clustering จะใช้ค่า Median เป็นค่ากลางของ Centroid ถ้าระยะห่าง ระหว่างค่า Median ของ Cluster คู่ใดต่ำจะรวม Cluster คู่นั้นเข้าด้วยกัน
 ในขณะที่วิธีของ Centroid Clustering จะให้ความสำคัญแก่ Cluster มีขนาดใหญ่มากกว่า Cluster ที่มีขนาดเล็ก (ให้น้ำหนักไม่เท่ากัน) Median Clustering จะใช้ค่า Median เป็นค่ากลางของ Centroid ถ้าระยะห่าง ระหว่างค่า Median ของ Clustering จะใช้ค่า Median เป็นค่ากลางของ Centroid ถ้าระยะห่าง ระหว่างค่า Median ของ Cluster คู่ใดต่ำจะรวม Cluster คู่นั้นเข้าด้วยกัน.")
45
7. Ward’s Method วิธีนี้จะพิจารณาจากค่า Sum of the squared within-cluster distance โดยจะรวม Cluster ที่ทำให้ค่า Sum of square within-cluster distance เพิ่มขึ้นน้อยที่สุด โดยค่า Square within-cluster distance คือค่า Square Euclidean distance ของแต่ละ Case กับ Cluster Mean

46
8. การพิจารณาเลือกจำนวนกลุ่มที่เหมาะสม
ผลลัพธ์ของเทคนิค Cluster ไม่ได้ให้ค่าสถิติ หรือผลการ ทดสอบสมมติฐานเพื่อให้ตัดสินใจหาจำนวนกลุ่มที่เหมาะสม ต้องพิจารณาความเหมาะสมเอง โดยอาจใช้ระยะห่างหรือความคล้ายโดยใช้ 1) การใช้ Dendogram สำหรับ Dendogram ถ้ากำหนดระยะห่างระหว่างกลุ่ม เป็นหน่วยที่แตกต่างกันไปก็จะได้จำนวน Cluster ที่แตกต่างกันไป คือยิ่งระห่างยิ่งมาก จำนวน Cluster ก็จะเพิ่มขึ้น 2) Multidimension Scaling 3) Discriminant
 การใช้ Dendogram สำหรับ Dendogram ถ้ากำหนดระยะห่างระหว่างกลุ่ม เป็นหน่วยที่แตกต่างกันไปก็จะได้จำนวน Cluster ที่แตกต่างกันไป คือยิ่งระห่างยิ่งมาก จำนวน Cluster ก็จะเพิ่มขึ้น. 2) Multidimension Scaling. 3) Discriminant.")
47
6.1.2 Divisive Hierarchical Cluster Analysis
คือ กลุ่มที่ประกอบด้วยสิ่งของ หรือ item จำนวน n สิ่ง แบ่งออกเป็น 2 กลุ่มชนิดที่สิ่งของในกลุ่มมีระยะทางไกลที่สุด ขั้นต่อไปก็จะมี 3 กลุ่มย่อย ทำเช่นนี้ต่อ ๆ ไป จะเห็นว่าในท้ายที่สุดแล้วจะมี n กลุ่มย่อยซึ่งแต่ละกลุ่มย่อยประกอบด้วยสิ่งของ 1 สิ่ง

48
9. การวิเคราะห์กลุ่มแบบไม่เป็นขั้นตอน (Nonhierarchical Cluster Analysis หรือบางครั้งเรียกว่า K – Means Cluster Analysis ) คือ ต้องกำหนดเองว่าจะต้องแบ่งเป็นกี่กลุ่ม เช่น k กลุ่ม จึงเรียกวิธีนี้ว่า K-Means Clustering สรุปได้ดังนี้

49
ขั้นตอนการจัดกลุ่มดังนี้
1. จัดสิ่งของออกเป็น K กลุ่ม คร่าว ๆ ก่อน 2. หา Centroid (ในที่นี้คือค่าเฉลี่ย) ของแต่ละกลุ่ม เราจะจัดสิ่งของลงในกลุ่มที่อยู่ใกล้ Centroid มากที่สุด ในกรณีที่กลุ่มที่จัดได้ในข้อ 1. ไม่เป็นไปตามนี้ เราต้องกลับไปเริ่มที่ข้อ 1. ใหม่ 3. กลับไปทำข้อ 2.
 ของแต่ละกลุ่ม เราจะจัดสิ่งของลงในกลุ่มที่อยู่ใกล้ Centroid มากที่สุด ในกรณีที่กลุ่มที่จัดได้ในข้อ 1. ไม่เป็นไปตามนี้ เราต้องกลับไปเริ่มที่ข้อ 1. ใหม่ 3. กลับไปทำข้อ 2.")
50
9.1 หลักการของเทคนิค K-Means Clustering
เป็นเทคนิคการจำแนก Case ออกเป็นกลุ่มย่อย จะใช้เมื่อมีจำนวน Case มาก โดยจะต้องกำหนดจำนวนกลุ่ม หรือจำนวน Cluster ที่ต้องการ เช่นกำหนดให้มี k กลุ่ม เทคนิค K-Means จะมีการทำงานหลาย ๆ รอบ (Iteration) โดยในแต่ละรอบจะมีการรวม Cases ให้ไปอยู่ในกลุ่มใดกลุ่มหนึ่ง โดยเลือกกลุ่มที่ Case นั้นมีระยะห่างจากค่ากลางของกลุ่มน้อยที่สุด แล้วคำนวณค่ากลางของกลุ่มใหม่ จะทำเช่นนี้จนกระทั่งค่ากลางของกลุ่มไม่เปลี่ยนแปลง หรือครบจำนวนรอบที่กำหนดไว้
 โดยในแต่ละรอบจะมีการรวม Cases ให้ไปอยู่ในกลุ่มใดกลุ่มหนึ่ง โดยเลือกกลุ่มที่ Case นั้นมีระยะห่างจากค่ากลางของกลุ่มน้อยที่สุด แล้วคำนวณค่ากลางของกลุ่มใหม่ จะทำเช่นนี้จนกระทั่งค่ากลางของกลุ่มไม่เปลี่ยนแปลง หรือครบจำนวนรอบที่กำหนดไว้")
51
9.2 ชนิดของตัวแปรที่ใช้ในเทคนิค K-Means Clustering
อันตรภาค (Interval Scale) หรือสเกลอัตราส่วน(Ratio Scale) โดยไม่สามารถใช้กับข้อมูลที่อยู่ในรูปความถี่ หรือ Binary เหมือนเทคนิค Hierarchical
 หรือสเกลอัตราส่วน(Ratio Scale) โดยไม่สามารถใช้กับข้อมูลที่อยู่ในรูปความถี่ หรือ Binary เหมือนเทคนิค Hierarchical.")
52
9.3 ขั้นตอนการวิเคราะห์ของวิธี K-Means มี 4 ขั้นตอนดังนี้
- แบ่งอย่างสุ่ม - แบ่งด้วยผู้ศึกษาเอง ขั้นที่ 2 คำนวณหาจุดกึ่งกลางกลุ่มของแต่ละกลุ่ม เช่น จุดกลางกลุ่มของกลุ่มที่ C คือ ขั้นที่ 3 มีวิธีการพิจารณา 2 แบบ โดยจะคำนวณ

53
แบบที่ 1 คำนวณหาระยะห่างจากแต่ละหน่วยไปยังจุดกลางกลุ่มของทุกกลุ่มและจะพิจารณาย้ายหน่วยไปยังกลุ่มที่มีระยะห่างต่ำสุด แบบที่ 2 คำนวณระยะห่างกำลังสองของแต่ละหน่วยไปยังจุดกลางกลุ่มที่หน่วยนั้นอยู่ โดยให้ ESSZ(Error Sum Square) เท่ากับระยะห่างกำลังสองของแต่ละหน่วยไปยังจุดกลางกลุ่ม สูตรที่ใช้
 เท่ากับระยะห่างกำลังสองของแต่ละหน่วยไปยังจุดกลางกลุ่ม สูตรที่ใช้")
54
ขั้นที่ 4 การพิจารณาย้ายกลุ่ม จะใช้เกณฑ์การย้ายตามค่าที่คำนวณได้ในขั้นที่ 3
ถ้าขั้นที่ 4 ไม่มีการย้ายกลุ่มอีกแล้ว แสดงว่ากลุ่มที่แบ่งได้นั้นเหมาะสมแล้ว แต่ถ้าในขั้นที่ 4 มีการย้ายกลุ่ม กลุ่มที่มีหน่วยย้ายเข้าหรือย้ายออกจะต้องทำการคำนวณหาจุดกลางกลุ่มใหม่นั้นคือต้องกลับไปทำขั้นที่ 2

55
9.4 ข้อแตกต่างระหว่างเทคนิค Hierarchical กับวิธี K-Means
1. เทคนิค K-Means ใช้เมื่อมีจำนวน Case หรือจำนวนข้อมูลมาก โดยทั่วไปนิยมใช้เมื่อ n ≥ 200 เพราะเมื่อ n มาก เทคนิค K-Means จะง่ายกว่า และใช้ระยะเวลาในการคำนวณน้อยกว่าการใช้เทคนิค Hierarchical หรือกล่าวได้ว่าเมื่อมีจำนวน Case ไม่มากควรใช้เทคนิค Hierarchical

56
2. เทคนิค K-Means นั้น ผู้ใช้จะต้องกำหนดจำนวนกลุ่มที่แน่นอนไว้ล่วงหน้า กรณีที่ผู้วิเคราะห์ยังไม่แน่ใจว่าควรมีกี่กลุ่มจึงจะเหมาะสม ผู้วิเคราะห์อาจจะใช้วิธีใดวิธีหนึ่งดังต่อไปนี้ ทำการวิเคราะห์ด้วยวิธี K-Means หลาย ๆ ครั้ง แต่ละครั้งกำหนด จำนวนกลุ่ม แตกต่างกันไป เช่น เป็น 3, 4 หรือ 5 กลุ่ม แล้วพิจารณา หาจำนวนกลุ่มที่เหมาะสม แต่เมื่อมีข้อมูลมากวิธีนี้จะทำให้เสียเวลามาก ใช้ข้อมูลบางส่วนทำการวิเคราะห์โดยวิธี Hierarchical เพื่อหาจำนวน กลุ่มที่ควรจะเป็นจากนั้นจึงใช้เทคนิค K-Means กับข้อมูลทั้งหมดที่มี

57
3. เทคนิค Hierarchical นั้น ผู้วิเคราะห์จะ Standardized ข้อมูลหรือไม่ก็ได้ แต่โดยวิธี K-Means จะต้องทำการ Standardized ข้อมูลก่อนเสมอ 4. วิธี K-Means จะหาระยะห่างโดยวิธี Euclidean Distance โดยอัตโนมัติ ขณะที่ Hierarchical ผู้วิเคราะห์มีสิทธิ์ที่จะเลือกวิธีการคำนวณระยะห่าง หรือความคล้ายได้

58
ข้อแตกต่างระหว่างการจำแนกกลุ่มด้วยเทคนิค
Cluster Analysis และเทคนิค Discriminant Analysis Cluster Analysis 1. ไม่จำเป็นต้องทราบก่อนว่ามีกี่กลุ่ม 2. ไม่ทราบมาก่อนว่า Case ใดอยู่กลุ่มไหน 3. ไม่มีสมการแสดงความสัมพันธ์ Discriminant Analysis 1. ต้องทราบมาก่อนว่ามีกี่กลุ่ม โดยผู้วิจัยเป็นผู้จัดกลุ่มเอง และกำหนดเอง จะมีกี่กลุ่ม 2. ทราบมาก่อนว่า Case ใดอยู่กลุ่มไหนเนื่องจากผู้วิจัยเป็นผู้จัดกลุ่มมาก่อน. 3. มีสมการแสดงความสัมพันธ์

59
ตัวอย่างการใช้เทคนิคต่าง ๆ
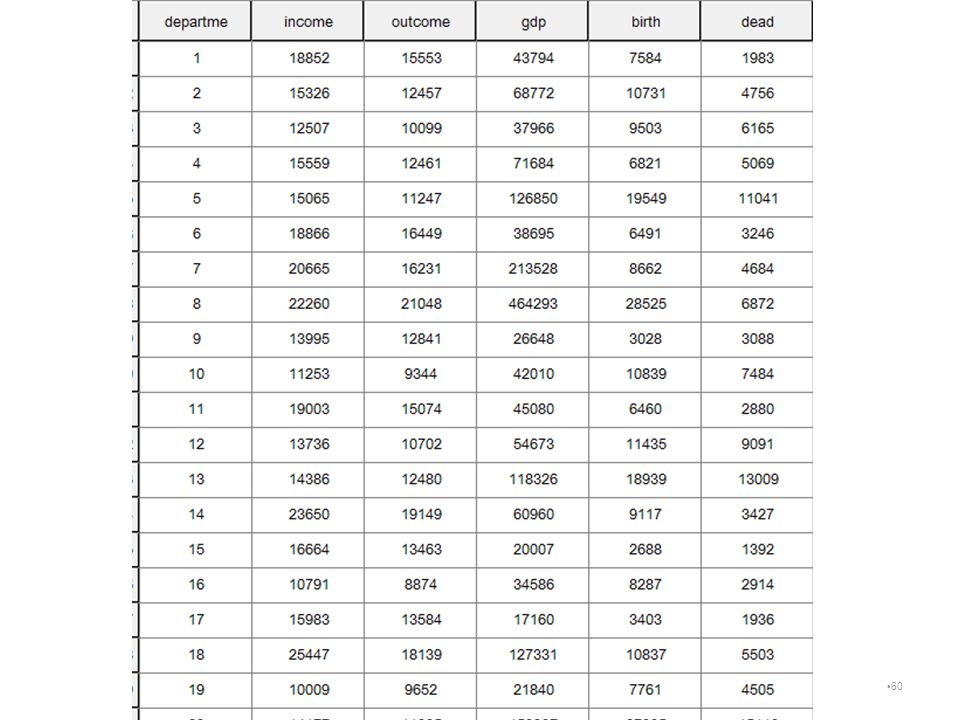
ตัวอย่างการใช้เทคนิค Hierarchical Cluster ในการจัดกลุ่ม การจัดกลุ่มจังหวัด ตัวแปรที่ใช้มี 5 ตัวแปร และข้อมูลที่ใช้เป็นข้อมูลปี 2550 1. ผลผลิตมวลรวมของจังหวัด ปี 2550 2. รายได้เฉลี่ยต่อครัวเรือน ปี 2550 3. รายจ่ายเฉลี่ยต่อครัวเรือน ปี 2550 4. จำนวนเด็กเกิดใหม่ ปี 2550 5. จำนวนผู้เสียชีวิต ปี 2550

61
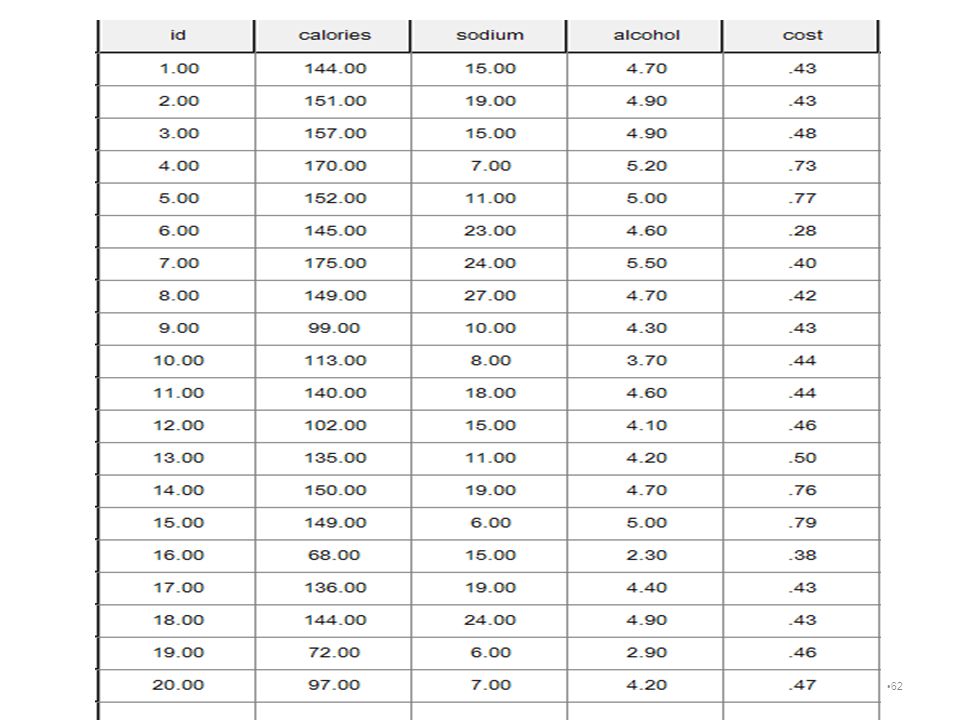
ตัวอย่าง ข้อมูลเกี่ยวกับเบียร์20ยี่ห้อผู้วิจัยต้องการทราบว่าเบียร์ทัง20ยี่ห้อนี้จะจัดรวมกันได้อย่างไรโดยพิจารณาจากตัวแปรต่างๆต่อไปนี้ calories, sodium, alcohol, cost 4/5/2017

งานนำเสนอที่คล้ายกัน









>")






>")


