ดาวน์โหลดงานนำเสนอ
งานนำเสนอกำลังจะดาวน์โหลด โปรดรอ

1
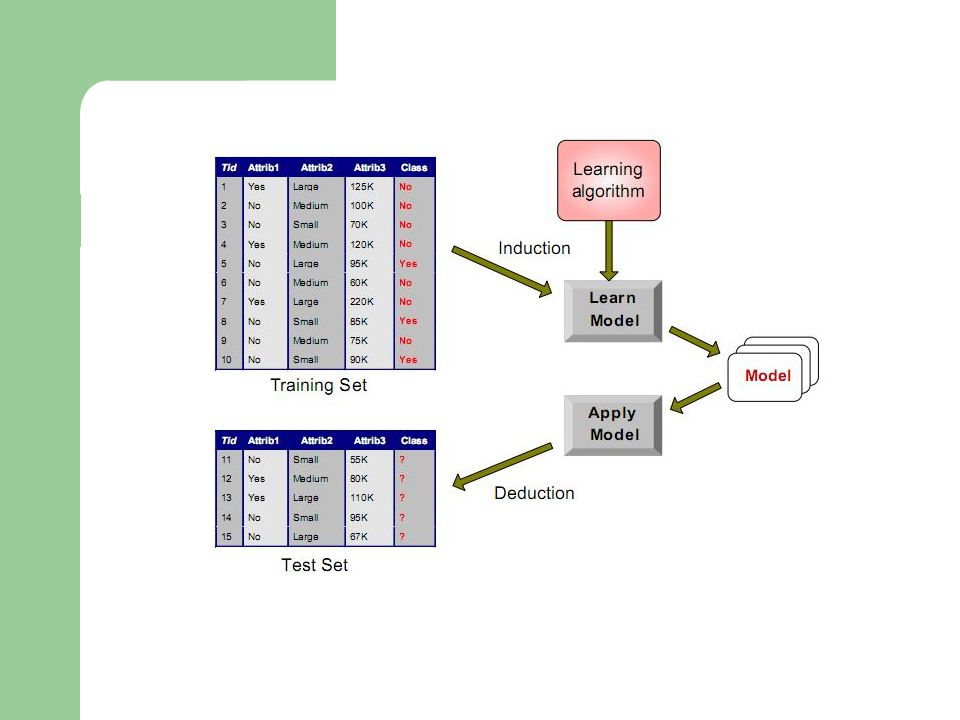
Classification Data mining การทำเหมืองข้อมูลแบบจำแนก
อ.วิวัฒน์ ชินนาทศิริกุล

2
Simple value Algorithm Naïve Bayes method Decision Tree induction
อัลกอริทึมที่ใช้ในการเหมืองข้อมูลแบบจำแนกได้แก่ Simple value Algorithm Naïve Bayes method Decision Tree induction Covering Algorithm

3
Classification : Definition

5
Decision Tree Example

6
Decision Tree Construction Process
แบ่งข้อมูลตัวอย่าง (Samples Data) ออกเป็น 3 ส่วนได้แก่ - Training Datasets - Validation Datasets - Test Datasets นำ Training Datasets มาสร้าง Decision Tree ใช้ Validation Datasets วัดความถูกต้องในการจำแนกของ Tree ที่สร้าง ทำซ้ำข้อ 2,3 เพื่อให้ได้ความถูกต้องสูงสุด ใช้ Testing Datasets มาสอบทดกับ Tree ที่ได้เพื่อวัดความถูกต้อง
 ออกเป็น 3 ส่วนได้แก่ - Training Datasets. - Validation Datasets. - Test Datasets. นำ Training Datasets มาสร้าง Decision Tree. ใช้ Validation Datasets วัดความถูกต้องในการจำแนกของ Tree ที่สร้าง. ทำซ้ำข้อ 2,3 เพื่อให้ได้ความถูกต้องสูงสุด. ใช้ Testing Datasets มาสอบทดกับ Tree ที่ได้เพื่อวัดความถูกต้อง.")
7
Decision Tree Learning Algorithm
- ID3 Algorithm - C4.5 Algorithm - C5.0 Algorithm - CART Algorithm

8
Decision Tree Induction
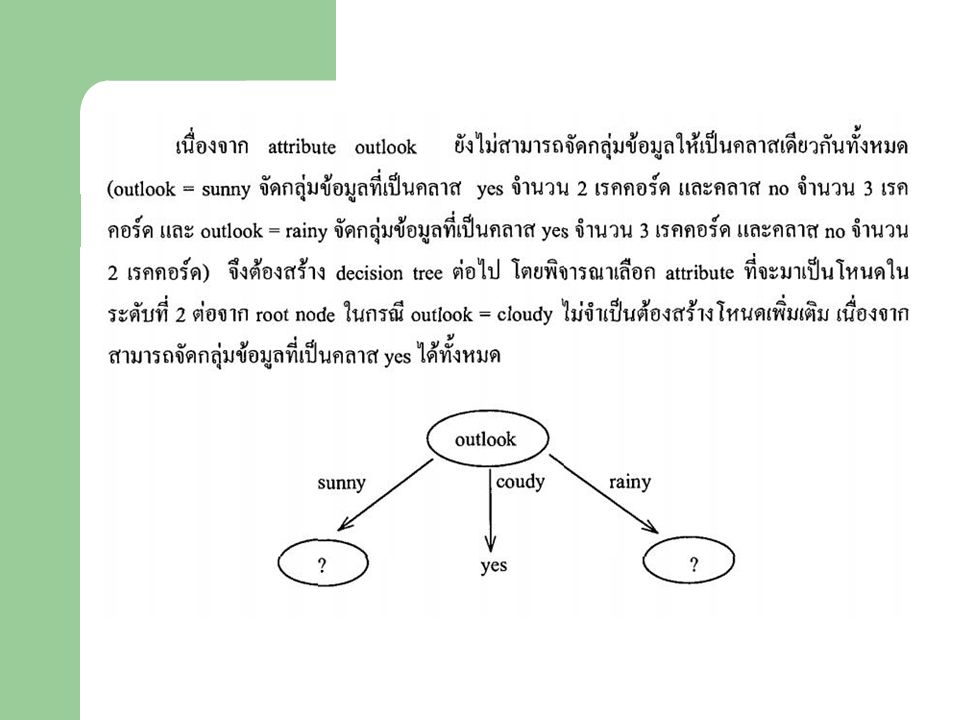
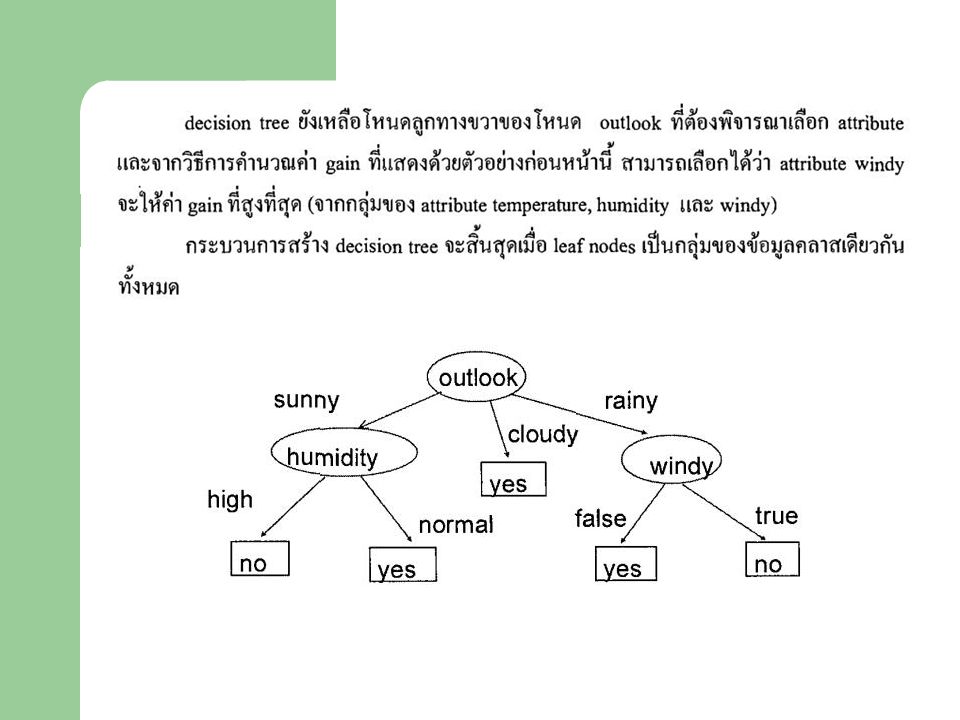
ขั้นตอนในการสร้าง Decision Tree จาก Training Datasets เพื่อใช้จำแนกข้อมูล มีดังนี้ 1. เลือก Attribute ที่ทำหน้าที่เป็น Root Node 2. จาก Root Node สร้างเส้นเชื่อมโยงไปยังโหนดลูก จำนวนเส้นเชื่อมโยง จะเท่ากับจำนวนค่าที่เป็นไปได้ทั้งหมดของ Attribute ที่เป็น root node 3. ถ้าโหนดลูก เป็นกลุ่มของข้อมูลที่อยู่ในคลาสเดียวกันทั้งหมด ให้หยุด สร้างต้นไม้ แต่ถ้าโหนดลูกมีข้อมูลของหลายคลาสปะปนกันอยู่ ต้อง สร้าง subtree เพื่อจำแนกข้อมูลต่อไป โดยเลือก subtree มาทำหน้าที่ เป็น root node ของ subtree มาทำซ้ำในขั้นตอนที่ 2,3

9
ID3 Algorithm use information theory to select the best attribute for
a decision at a node The idea is to select an attribute that yields the highest information gain

10
Classification Sample Data

11
ขณะที่ แอททริบิวต์ outlook , temperature , humidity , windy ทำ
ข้อมูลที่กำหนดในตาราง เป็นข้อมูลสภาพอากาศ ที่ใช้ประกอบการ ตัดสินใจในการเล่นกีฬาชนิดหนึ่ง ว่า มีสภาพอากาศอย่างไรจึงจะเล่น (play = yes) มีสภาพอากาศอย่างไรจึงไม่เล่น (play = no) ในงาน จำแนกข้อมูล (Classification) ข้อมูลที่เป็นจุดมุ่งหมายใน การจำแนก คือ แอททริบิวต์ play ขณะที่ แอททริบิวต์ outlook , temperature , humidity , windy ทำ หน้าที่เป็น predicting attributes
 มีสภาพอากาศอย่างไรจึงไม่เล่น (play = no) ในงาน จำแนกข้อมูล (Classification) ข้อมูลที่เป็นจุดมุ่งหมายใน. การจำแนก คือ แอททริบิวต์ play. ขณะที่ แอททริบิวต์ outlook , temperature , humidity , windy ทำ. หน้าที่เป็น predicting attributes.")
12
ปัญหาที่ต้องพิจารณาคือ จะเลือก Attributes ใด ทำหน้าที่เป็น
root node ในแต่ขั้นตอนของการสร้าง tree และ subtree เกณฑ์ที่ช่วยตัดสินใจ ในการเลือก root node คือ ทดลองเลือก Attribute แต่ละตัวมาทำหน้าที่เป็น root node แล้วหาค่า Gain ซึ่งเป็นค่าที่ใช้บอกว่า attribute ที่ทำหน้าที่เป็น root node สามารถจำแนกข้อมูลได้ดีมากน้อยเพียงใด จะเลือก attribute ที่ให้ค่า Gain สูงสุด

13
Gain เป็นค่าที่บอกระดับความสามารถของการจำแนกคลาสของ attribute
หน่วยของการวัดเป็น bits ถ้าให้ T แทน เซตของ Training Set X แทน แอททริบิวต์ ที่ถูกเลือกให้เป็นตัวจำแนกข้อมูล Gain(x) = info(T) – infox(T)
 = info(T) – infox(T)")
14
Info(T) เป็นฟังก์ชัน ที่ระบุปริมาณข้อมูลที่ต้องการเพื่อให้สามารถจำแนก
คลาสที่ต้องการได้ info(T) = เมื่อ |T| คือ จำนวนข้อมูลทั้งหมดใน Training Datasets Freq(Cj,T) คือ ความถี่ที่ข้อมูลใน T ปรากฏเป็นคลาส Cj
 = เมื่อ |T| คือ จำนวนข้อมูลทั้งหมดใน Training Datasets. Freq(Cj,T) คือ ความถี่ที่ข้อมูลใน T ปรากฏเป็นคลาส Cj.")
15
Infox(T) คือ ฟังก์ชันที่ระบุปริมาณข้อมูลที่ต้องการเพื่อการจำแนกคลาส
ของข้อมูลโดยใช้ attribute X เป็นตัวตรวจสอบเพื่อแยกข้อมูล Infox(T) = เมื่อ i คือ จำนวนค่าที่เป็นไปได้ของแอททริบิวต์ x |Ti| คือ จำนวนข้อมูลที่มีค่า x=i
 = เมื่อ i คือ จำนวนค่าที่เป็นไปได้ของแอททริบิวต์ x. |Ti| คือ จำนวนข้อมูลที่มีค่า x=i.")
16
จากตัวอย่างข้อมูลจะหาค่า gain ของแต่ละ attribute ที่จะเลือกเป็น
Root node 1. จะต้องหาค่า info(T)
")
17
2. หาค่า infox(T) ของแต่ละแอททริบิวต์
ค่า infooutlook(T) หาได้ดังนี้
 หาได้ดังนี้")
28
แบบฝึกหัด จากข้อมูล ความคิดเห็นของคน 7 คน ที่ต้องการเลือกผู้สมัคร
หมายเลข 1 หรือ หมายเลข 2 โดยพิจารณาจากอายุ รายได้ และการศึกษา ของผู้แสดงความคิดเห็น ปรากฎดังตาราง ให้สร้าง Decision Tree โดยใช้ ID3 Algorithm No Age Income Education Candidate 1 >=35 High High School 2 <35 Low University 3 College 4 5 6 7

งานนำเสนอที่คล้ายกัน











>")






>")









