ดาวน์โหลดงานนำเสนอ
งานนำเสนอกำลังจะดาวน์โหลด โปรดรอ

1
Chapter 5: Instance-Based Learning
Dr.Noppamas Pukkhem

2
Classification vs. Prediction
predicts categorical class labels classifies data (constructs a model) based on the training set and the values (class labels) in a classifying attribute and uses it in classifying new data Prediction: models continuous-valued functions, i.e., predicts unknown or missing values Typical Applications credit approval target marketing medical diagnosis treatment effectiveness analysis
 based on the training set and the values (class labels) in a classifying attribute and uses it in classifying new data. Prediction: models continuous-valued functions, i.e., predicts unknown or missing values. Typical Applications. credit approval. target marketing. medical diagnosis. treatment effectiveness analysis.")
3
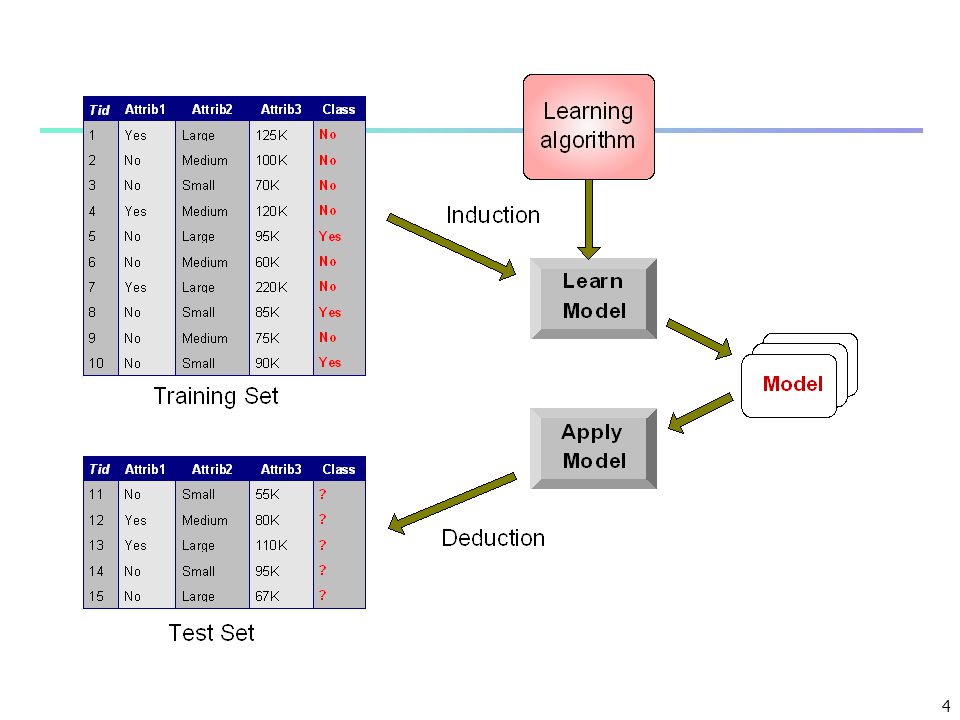
Classification—A Two-Step Process
Step 1 - Model construction describe a set of predetermined classes Each tuple/sample is assumed to belong to a predefined class, as determined by the class label attribute The set of tuples used for model construction is the training set The model is represented as classification rules, decision trees, or mathematical formulae Step 2 - Model usage Estimate accuracy of the model The known label of test sample is compared with the classified result from the model Accuracy rate is the percentage of test set samples that are correctly classified by the model Test set is independent of training set Use model to classify future or unknown objects

5
Classification Process (1): Model Construction
Algorithms Training Data Classifier (Model) IF rank = ‘professor’ OR years > 6 THEN tenured = ‘yes’
 IF rank = ‘professor’ OR years > 6. THEN tenured = ‘yes’")
6
Classification Process (2): Use the Model in Prediction
Classifier Accuracy != 100 Testing Data Unseen Data (Jeff, Professor, 4) Tenured?
 Tenured")
7
Lazy vs. Eager Learning Lazy vs. eager learning
Lazy learning (e.g., instance-based learning): Simply stores training data (or only minor processing) and waits until it is given a test tuple Eager learning (eg. Decision trees, SVM, NN): Given a set of training set, constructs a classification model before receiving new (e.g., test) data to classify Lazy: less time in training but more time in predicting Accuracy Lazy method effectively uses a richer hypothesis space since it uses many local linear functions to form its implicit global approximation to the target function Eager: must commit to a single hypothesis that covers the entire instance space
: Simply stores training data (or only minor processing) and waits until it is given a test tuple. Eager learning (eg. Decision trees, SVM, NN): Given a set of training set, constructs a classification model before receiving new (e.g., test) data to classify. Lazy: less time in training but more time in predicting. Accuracy. Lazy method effectively uses a richer hypothesis space since it uses many local linear functions to form its implicit global approximation to the target function. Eager: must commit to a single hypothesis that covers the entire instance space.")
8
Lazy vs. Eager Learning Its very similar to a Desktop!! Eager
Survey before Lazy Desktop Its very similar to a Desktop!!

9
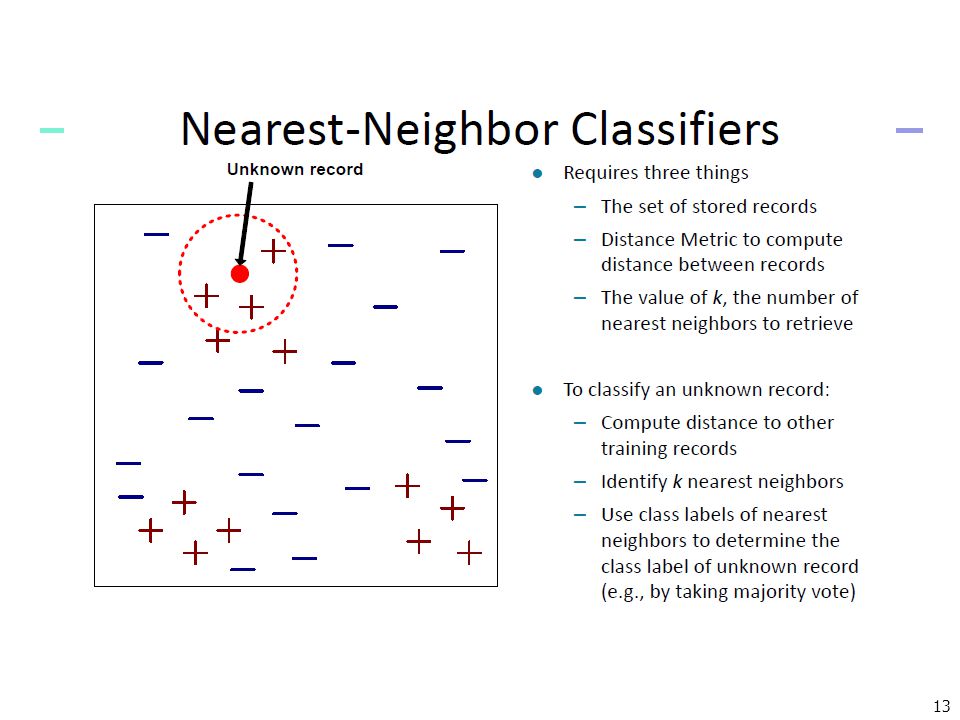
Lazy Learner: Instance-Based Methods
Instance-based learning: Store training examples and delay the processing (“lazy evaluation”) until a new instance must be classified Typical approaches k-nearest neighbor approach Instances represented as points in a Euclidean space. Locally weighted regression Constructs local approximation
 until a new instance must be classified. Typical approaches. k-nearest neighbor approach. Instances represented as points in a Euclidean space. Locally weighted regression. Constructs local approximation.")
10
Instance-Based Methods

12
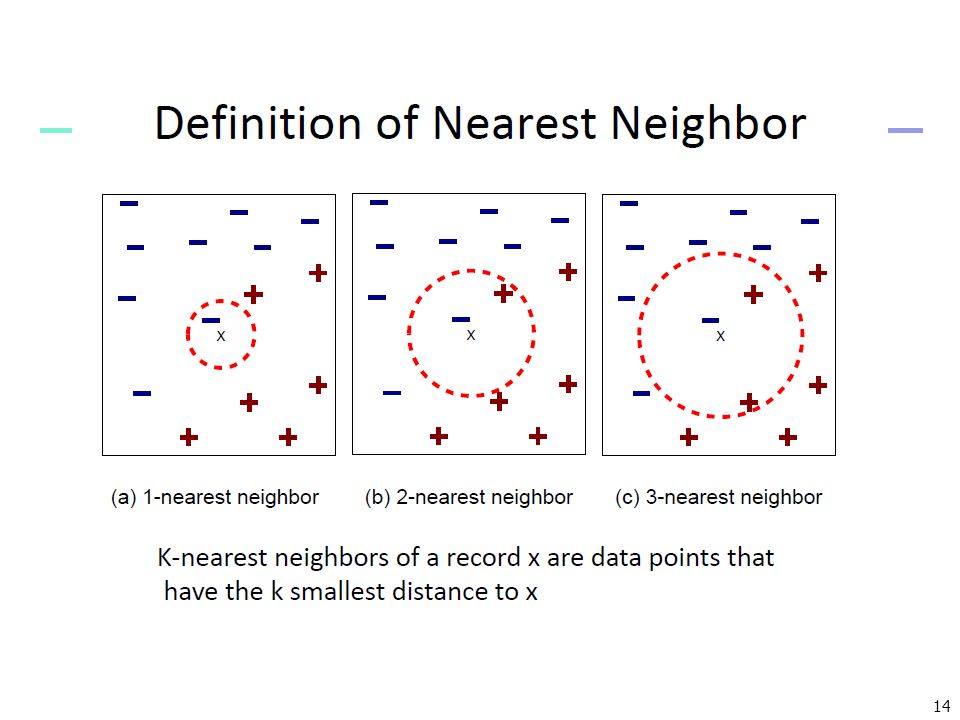
The k-Nearest Neighbor Algorithm
All instances correspond to points in the n-D space. The nearest neighbor are defined in terms of Euclidean distance. The target function could be discrete- or real- valued. For discrete-valued, the k-NN returns the most common value among the k training examples nearest to xq. Vonoroi diagram: the decision surface induced by 1-NN for a typical set of training examples. . _ _ . _ _ + . . + . _ xq + . _ +

15
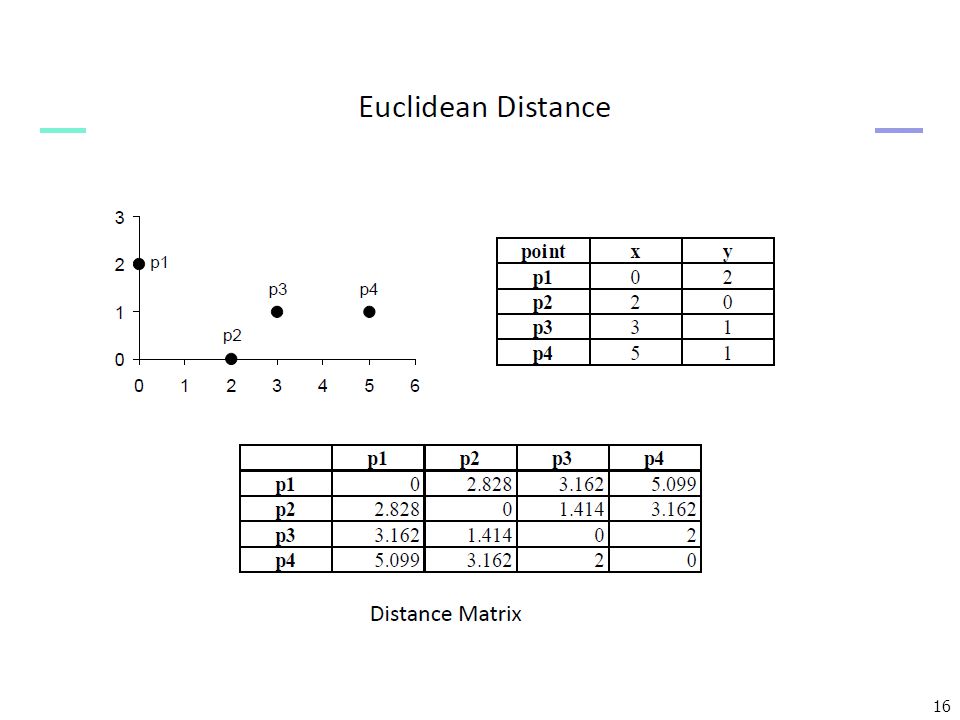
Euclidean Distance

17
การกำหนดตัวแปร K ไม่ควรเลือก K เล็กเกินไป เพราะจะทำให้เบี่ยงเบนสูง
เพราะฉะนั้นการเลือกค่า K ขึ้นอยู่กับข้อมูล ต้องมีการปรับค่าการประเมิน เช่น Cross-validation ระยะทางที่ใช้วัด คือ ถ้า x ประกอบไปด้วย Attribute <a1(x), a2(x), …, an(x)> ดังนั้น ar(x) ดังกล่าวจึงแทนด้วยค่าในด้วย x ค่าระยะทางที่ใช้ เรียกว่า Euclidean Distance
, a2(x), …, an(x)> ดังนั้น ar(x) ดังกล่าวจึงแทนด้วยค่าในด้วย x. ค่าระยะทางที่ใช้ เรียกว่า Euclidean Distance.")
18
อัลกอริทึมเพื่อนบ้านใกล้สุด k ตัว (k-Nearest Neighbor :k-NN)
จะตัดสินใจ ว่าคลาสใดที่จะแทนเงื่อนไขหรือกรณีใหม่ๆ ได้ ตรวจสอบจำนวนบางจำนวน (“k” ใน k-Nearest Neighbor) ของกรณีหรือเงื่อนไขที่เหมือนกันหรือใกล้เคียงกันมากที่สุด โดย จะหาผลรวมของจำนวนเงื่อนไข หรือกรณีต่างๆ สำหรับแต่ละ คลาส กำหนดเงื่อนไขใหม่ๆ ให้คลาสที่เหมือนกันกับคลาสที่ ใกล้เคียงกันมากที่สุด
 ของกรณีหรือเงื่อนไขที่เหมือนกันหรือใกล้เคียงกันมากที่สุด โดย จะหาผลรวมของจำนวนเงื่อนไข หรือกรณีต่างๆ สำหรับแต่ละ คลาส. กำหนดเงื่อนไขใหม่ๆ ให้คลาสที่เหมือนกันกับคลาสที่ ใกล้เคียงกันมากที่สุด.")
19
การเรียนรู้ของอัลกอริทึม k-NN
เมื่อมีการกำหนดตัวอย่างค้นถาม Xq แล้ว การเรียนรู้ ประกอบด้วย 2 ขั้นตอน 1. ใช้มาตรวัดระยะห่างคำนวณหาตัวอย่าง k ตัวที่อยู่ใกล้ Xq มากที่สุดจากเซตตัวอย่างสอน 2. ประมาณค่าฟังก์ชั่นเป้าหมายของตัวอย่างค้นถาม Xq ด้วย ค่าฟังก์ชั่นเป้าหมายของตัวอย่าง Xi จำนวน k ตัวที่อยู่ใกล้ Xq มากที่สุด

20
การเรียนรู้ของอัลกอริทึม k-NN
ประมาณค่าฟังก์ชั่นเป้าหมายของตัวอย่างค้นถาม Xq ค่าฟังก์ชั่นเป้าหมายเป็นค่าไม่ต่อเนื่อง เลือกค่าส่วนมาก ของค่าฟังก์ชั่นเป้าหมายของตัวอย่าง Xi จำนวน k ตัวที่อยู่ ใกล้ Xq มากที่สุด

21
การเรียนรู้ของอัลกอริทึม k-NN
ค่าฟังก์ชั่นเป้าหมายเป็นค่าจำนวนจริง ค่าเฉลี่ยของค่า ฟังก์ชั่นเป้าหมายของตัวอย่าง Xi จำนวน k ตัวที่อยู่ใกล้ Xq มาก ที่สุด

22
k-NN แบบถ่วงน้ำหนักด้วยระยะทาง (Distance-Weighted k-NN)
ผลเสียคือการทำงานของจำแนกประเภทจะช้าลง ในการปรับ kNN ให้ละเอียดขึ้น โดยการให้น้ำหนักที่ มากกว่ากับตัวอย่างที่ใกล้กับตัวอย่างค้นถามมากกว่า การ คำนวณค่าน้ำหนัก ใช้สมการ

23
k-NN แบบถ่วงน้ำหนักด้วยระยะทาง (Distance-Weighted k-NN)
โดยใช้สมการสำหรับฟังก์ชั่นเป้าหมายที่เป็นค่าไม่ต่อเนื่อง (Discrete-Valued Target Functions) และใช้สมการสำหรับฟังก์ชั่นเป้าหมายที่เป็นค่าต่อเนื่อง (Real-Valued Target Functions)
 และใช้สมการสำหรับฟังก์ชั่นเป้าหมายที่เป็นค่าต่อเนื่อง (Real-Valued Target Functions)")
24
ทางเลือกค่าความผิดพลาด
ทางเลือกนิยามค่าความผิดพลาดที่เป็นไปได้ 3 แบบคือ Squared error over k Nearest Neighbors Distance-weighted squared error over the entire set D of training data Combine 1 and 2 หมายเหตุ K คือ เคอร์เนลฟังก์ชั่น หรือ ฟังก์ชั่นผกผัน (inverse function) กับระยะห่าง ใช้เพื่อ กำหนดน้ำหนักสำหรับตัวอย่างสอนแต่ละตัว
 กับระยะห่าง ใช้เพื่อ กำหนดน้ำหนักสำหรับตัวอย่างสอนแต่ละตัว.")
25
ข้อดีและข้อเสียของ k-NN
สามารถจำลองฟังก์ชั่นเป้าหมายที่ซับซ้อนด้วยชุดของ ค่าประมาณแบบท้องถิ่นที่ซับซ้อนได้ สารสนเทศที่ปรากฎอยู่ในชุดข้อมูลสอนไม่สูญหาย เนื่องจากถูกจัดเก็บแยกไว้ต่างหาก เวลาที่ใช้สอนจะรวดเร็ว เนื่องจากการเป็นการเรียนรู้แบบ เกียจคร้าน

26
ข้อดีและข้อเสียของ k-NN
ค่าใช้จ่ายตอนจำแนกประเภทสูง เนื่องจากการคำนวณเกิดขึ้นขณะค้น ถามมากกว่าตอนสอน ความยากในการกำหนดมาตรวัดระยะห่างที่เหมาะสม วิธีจำแนกประเภทแบบเพื่อนบ้านใกล้สุด k ตัว เหมาะกับชุดข้อมูลสอนที่มี ปริมาณมาก และตัวอย่างมีคุณลักษณะไม่เกิน 20 คุณลักษณะ ต้องการวิธีการจัดทำดัชนีหน่วยความจำ (Memory Indexing) ที่มี ประสิทธิภาพ (มีการจัดเก็บตัวอย่างสอนไว้ต่างหาก) ผลกระทบเชิงลบจากคุณลักษณะที่ไม่เกี่ยวข้อง ต่อมาตรวัดระยะห่าง หรือ การเกิด Curse of Dimensionality
 ที่มี ประสิทธิภาพ (มีการจัดเก็บตัวอย่างสอนไว้ต่างหาก) ผลกระทบเชิงลบจากคุณลักษณะที่ไม่เกี่ยวข้อง ต่อมาตรวัดระยะห่าง หรือ การเกิด Curse of Dimensionality.")
27
สรุป การเรียนรู้เชิงอินสแตนซ์ เป็นการสร้างแบบจำลองการ จำแนกประเภทรูปแบบหนึ่ง ที่มีการเรียนรู้แบบเกียจคร้าน อัลกอริทึมหลักที่ใช้คือ อัลกอริทึมเพื่อนบ้านใกล้สุด k ตัว ซึ่งมีการปรับให้มีความเหมาะสมมากขึ้นด้วยวิธีการกำหนดค่า น้ำหนักของคลาสเป้าหมายตามระยะทางกับตัวค้นถาม อย่างไรก็นอกเหนือจากข้อดีในการทำงานได้อย่าง รวดเร็วแล้ว อัลกอริทึมแบบ k-NN ก็มีข้อจำกัดในเรื่องของการ นำไปใช้กับข้อมูลที่มีคุณสมบัติจำนวนมาก

28
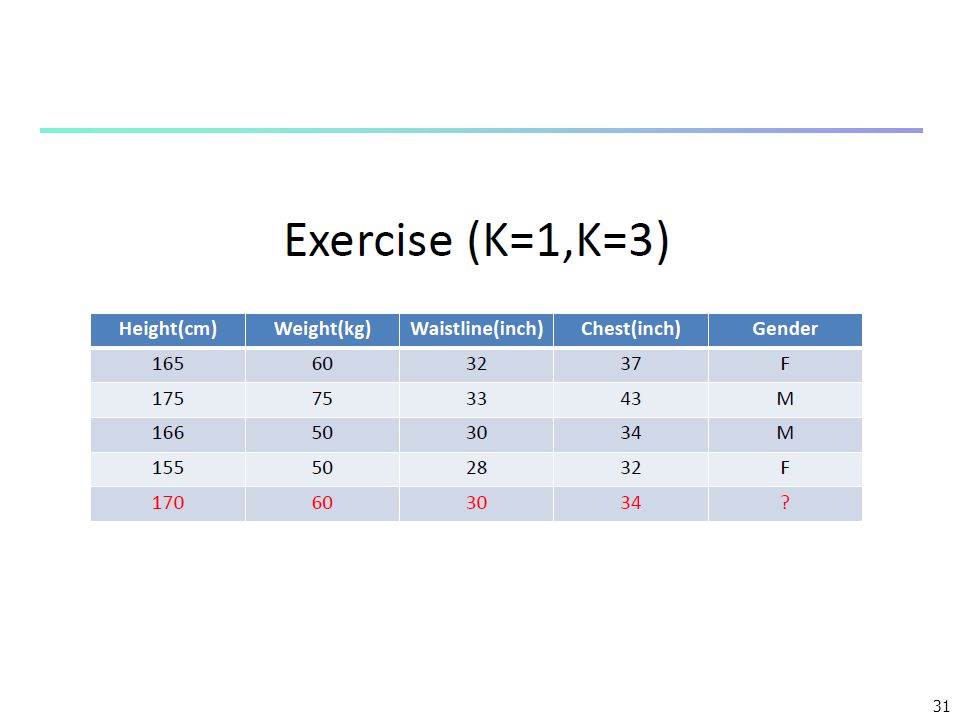
Example

29
x = <humidity, temperature>
Euclidean Distance Discrete values Humidity temperature Run 30 25 + 48 40 - 80 64 28 50 60 x = <humidity, temperature> New instance xq = <40, 30, run=?? > We can run inside(+) or outside (-) 1-NN (x1) Answer run inside(+) 2-NN (x1,x4) 3-NN (x1,x2,x4) Answer run inside (+) 4-NN (x1,x2,x4,x5) 5-NN Answer run inside(-)
 or outside (-) 1-NN (x1) Answer run inside(+) 2-NN (x1,x4) 3-NN (x1,x2,x4) Answer run inside (+) 4-NN (x1,x2,x4,x5) 5-NN. Answer run inside(-)")
30
Euclidean Distance Real values Humidity temperature Rainfall 30 25 5.1
48 40 15.5 80 64 20.2 28 3.2 50 60 12.0 1-NN (x1) Rainfall = 5.1 2-NN (x1,x4) Rainfall = ( )/2 = 4.15 3-NN (x1,x2,x4) Rainfall = ( )/3 = 7.9 4-NN (x1,x2,x4,x5) Rainfall = ( )/4 = 8.95 5-NN (x1,x2,x3, x4,x5) Rainfall = ( )/5 = 11.2 x = <humidity, temperature> New instance xq = <40, 30, Rainfall =?? >
 Rainfall = NN (x1,x4) Rainfall = ( )/2 = NN (x1,x2,x4) Rainfall = ( )/3. = NN (x1,x2,x4,x5) Rainfall = ( )/4 = NN (x1,x2,x3, x4,x5) Rainfall = ( )/5 = x = <humidity, temperature> New instance xq = <40, 30, Rainfall = >")
งานนำเสนอที่คล้ายกัน

>")





>")




>")






 within the product or service. An item is classified as a.>")
