INC 637 Artificial Intelligence Lecture 13 Reinforcement Learning (RL) (continue)
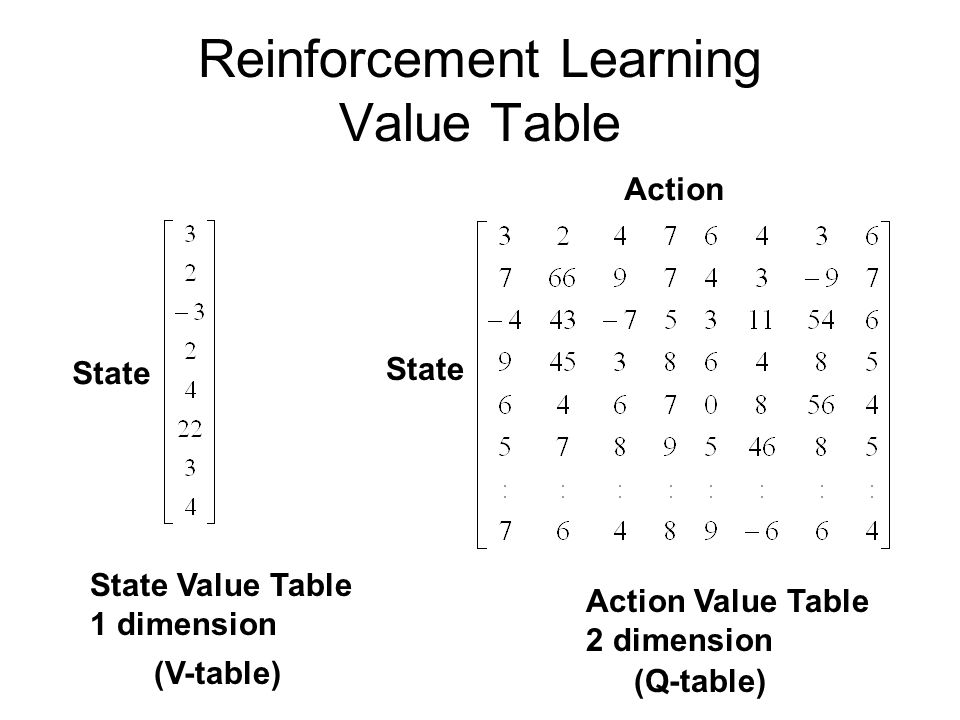
Reinforcement Learning Value Table State Value Table 1 dimension State Action Value Table 2 dimension State Action (Q-table) (V-table)
Bellman Equation for a Policy So: Or, without the expectation operator: คำนวณหา Value Function จาก policy π
Bellman Optimality Equation for V* The value of a state under an optimal policy must equal the expected return for the best action from that state:
3 Methods to find V* Dynamic Programming Monte Carlo Temporal Difference
Dynamic Programming Policy EvaluationPolicy Improvement ประกอบด้วยขบวนการหลัก 2 ส่วน
Policy Evaluation แต่ละ state มีสมการของตัวเองซึ่งขื้นกับ value function ของ next state เป็นสมการ linear หลายตัวแปร อย่างไรก็ตาม ก็ยังยากที่จะแก้สมการถ้ามีหลายๆ state
Iterative Policy Evaluation a “sweep” A sweep consists of applying a backup operation to each state. ตือใช้ value function จาก อันก่อนมาประมาณอันปัจจุบัน A full policy evaluation backup:
Example Undiscounted episodic task Actions that would take agent off the grid leave state unchanged Reward is –1 for every action until the terminal state is reached Terminal state
(0.25(-1+0.0) (-1-1.0) (-1-1.0) (-1-1.0)
Policy Improvement สามารถทำได้จาก value function ที่คำนวณได้มาโดยปรับ ให้ไปเลือก action ที่มี value function สูงสุด เรียกว่าเป็น greedy actions
Iterative Policy Improvement policy evaluationpolicy improvement “greedification” การ estimate ค่า value function โดยใช้ค่า estimate ของมันเองเรียก Bootstrapping
Dynamic Programming
Monte Carlo Method Dynamic Programming ต้องรู้ world model นั่นคือมี reward เท่าใด ที่ไหมบ้าง และ next state เป็นอะไร Monte Carlo จะไม่ต้องรู้ world model มาก่อน คุณสมบัติของ Monte Carlo ใช้ได้กับ episodic tasks เท่านั้น learn จาก ประสบการณ์จริงโดยใช้ complete returned reward
Monte Carlo Policy Evaluation Goal: learn V (s) Given: some number of episodes under which contain s Idea: Average returns observed after visits to s Every-Visit MC: average returns for every time s is visited in an episode First-visit MC: average returns only for first time s is visited in an episode Both converge asymptotically 12345
Backup Diagram of MC Entire episode included Only one choice at each state (unlike DP) MC does not bootstrap Time required to estimate one state does not depend on the total number of states Series of actions s1 s2 s3 a1 a2 a3
Monte Carlo Policy Iteration Policy Improvement
Example: Blackjack Object: Have your card sum be greater than the dealers without exceeding 21. States (200 of them): –current sum (12-21) –dealer’s showing card (ace-10) –do I have a useable ace? Reward: +1 for winning, 0 for a draw, -1 for losing Actions: stick (stop receiving cards), hit (receive another card) Policy: Stick if my sum is 20 or 21, else hit
เช่นในสถานะการหนึ่งไม่มี usable ace และ เจ้ามือ show 8 เราเริ่มต้นที่ แต้ม = 12 จั่วได้ เป็น 14 และ 18 แล้วดูผลว่าแพ้หรือชนะ จะนำค่าผลลัพธืที่ได้มา update state ที่ 12, 14, 18 นี้ ทำไปหลายหมื่นครั้งจะได้กราฟของทุก state ดังรูป
Temporal Difference (TD) Policy Evaluation (the prediction problem): for a given policy , compute the state-value function Recall: target: the actual return after time t target: an estimate of the return
Simple Monte Carlo TTTTTTTTTT
Simplest TD Method TTTTTTTTTT
Dynamic Programming T T T TTTTTTTTTT
TD Bootstraps and Samples Bootstrapping: update involves an estimate –MC does not bootstrap –DP bootstraps –TD bootstraps Sampling: update does not involve an expected value –MC samples –DP does not sample –TD samples
Learning an Action-Value Function
Sarsa: On-Policy TD ที่เป็น on-policy เพราะต้องทำ action ก่อนเพื่อให้ได้ next state แล้วค่อยนำมา update value table
Q-learning Off-Policy TD ที่เป็น off-policy เพราะไม่ต้องทำตาม next state ที่จะเลือกเอา action ที่ได้ reward สูงสุด
Current state Action ไปทางขวา Next state