ดาวน์โหลดงานนำเสนอ
1
บทที่ 9 การกำหนดขนาดของตัวอย่าง
บทที่ 9 การกำหนดขนาดของตัวอย่าง ความคลาดเคลื่อนจากการสุ่ม ขนาดตัวอย่าง

2
ปัจจัยพื้นฐานในการกำหนดขนาดตัวอย่าง
1. ลักษณะของประชากร ประชากรที่มีลักษณะทางประชากรแตกต่างกันมาก (Heterogeneous)ต้องใช้จำนวนตัวอย่างมากกว่ากรณีที่ลักษณะของประชากรมีความเหมือนกัน (Homogeneous) ผู้ใช้แรงงาน ผู้บริหาร
ต้องใช้จำนวนตัวอย่างมากกว่ากรณีที่ลักษณะของประชากรมีความเหมือนกัน (Homogeneous) ผู้ใช้แรงงาน. ผู้บริหาร.")
3
ขนาดตัวอย่างอาจมีขนาดเล็กได้ ขนาดตัวอย่างควรมีขนาดใหญ่
2. ประเภทของการวิจัย การวิจัยแบบสืบเสาะ (Exporatory research) ขนาดตัวอย่างอาจมีขนาดเล็กได้ การวิจัยเชิงทดลอง (Experimental research) การวิจัยเชิงคุณภาพ (Qualitative research) ขนาดตัวอย่างควรมีขนาดใหญ่ การวิจัยแบบพรรณนา (Descriptive research) การวิจัยเชิงเหตุผล (Causual research)
 ขนาดตัวอย่างอาจมีขนาดเล็กได้ การวิจัยเชิงทดลอง (Experimental research) การวิจัยเชิงคุณภาพ (Qualitative research) ขนาดตัวอย่างควรมีขนาดใหญ่ การวิจัยแบบพรรณนา (Descriptive research) การวิจัยเชิงเหตุผล (Causual research)")
4
3. วิธีการวิเคราะห์ข้อมูล
3. วิธีการวิเคราะห์ข้อมูล ถ้าผู้วิจัยใช้สถิติที่ใช้พารามิเตอร์ (Parametric Statistics) จำนวน ตัวอย่างที่ใช้ต้องไม่น้อยกว่า 30 ตัวอย่าง แต่ถ้าเป็นการวิจัยเชิงคุณภาพ และใช้สถิติที่ไม่ใช้พารามิเตอร์ (Nonparametric Statistics) จำนวนตัวอย่างอาจจะไม่ถึง ตัวอย่างก็ได้ นอกจากนี้การวิจัยที่มีความสลับซับซ้อน เช่น Multivariate Statistic จำนวนตัวอย่างก็ควรมีขนาดใหญ่
 จำนวน ตัวอย่างที่ใช้ต้องไม่น้อยกว่า 30 ตัวอย่าง. แต่ถ้าเป็นการวิจัยเชิงคุณภาพ และใช้สถิติที่ไม่ใช้พารามิเตอร์ (Nonparametric Statistics) จำนวนตัวอย่างอาจจะไม่ถึง 30 ตัวอย่างก็ได้ นอกจากนี้การวิจัยที่มีความสลับซับซ้อน เช่น Multivariate Statistic จำนวนตัวอย่างก็ควรมีขนาดใหญ่")
5
ในกรณีศึกษาความเป็นอิสระต่อกันระหว่างตัวแปร 2 ตัวที่มีระดับการวัดเป็นนามบัญญัติ (Nominal Scale) โดยใช้วิธีการวิเคราะห์ ไคว์-สแควร์ (Chi - Square) ผู้วิจัยต้องคำนึงว่าจำนวนตัวอย่างที่คาดหมาย (ei) ในแต่ละช่อง (Cell) ของตารางการจรณ์ (Contigency Table) อย่างน้อยควรมีจำนวนไม่น้อยกว่า 5 ราย ดังนั้นถ้าตัวแปรที่นำมาวิเคราะห์มีหลายกลุ่ม จำนวนตัวอย่างก็จะต้องมีมากขึ้น หรือในการวิเคราะห์จำแนกประเภท (Discriminant Analysis) จำนวนตัวอย่างของแต่ละกลุ่มของตัวแปรตามจะต้องมีมากเพียงพอที่จะนำมาวิเคราะห์ได้
 โดยใช้วิธีการวิเคราะห์ ไคว์-สแควร์ (Chi - Square) ผู้วิจัยต้องคำนึงว่าจำนวนตัวอย่างที่คาดหมาย (ei) ในแต่ละช่อง (Cell) ของตารางการจรณ์ (Contigency Table) อย่างน้อยควรมีจำนวนไม่น้อยกว่า 5 ราย ดังนั้นถ้าตัวแปรที่นำมาวิเคราะห์มีหลายกลุ่ม จำนวนตัวอย่างก็จะต้องมีมากขึ้น หรือในการวิเคราะห์จำแนกประเภท (Discriminant Analysis) จำนวนตัวอย่างของแต่ละกลุ่มของตัวแปรตามจะต้องมีมากเพียงพอที่จะนำมาวิเคราะห์ได้")
6
สถิติพาราเมตริก (Parametric statistics)
คือ อนุมานสถิติในลักษณะที่มีการอ้างอิงค่าสถิติ ซึ่งเป็นค่าที่คำนวณได้จากกลุ่มตัวอย่างกลับไปสู่ค่าพารามิเตอร์ ซึ่งเป็นค่าของกลุ่มประชากร ซึ่งมีข้อตกลงเบื้องต้นดังนี้ - กลุ่มตัวอย่างของข้อมูลมีการแจกแจงเป็นโค้งปกติ - ความแปรปรวนของกลุ่มประชากรทุกกลุ่มต้องเท่ากัน - ข้อมูลแต่ละตัวมีความเป็นอิสระต่อกันทั้งภายในกลุ่ม และระหว่างกลุ่ม - ข้อมูลเป็นชนิดอันตรภาค (Interval data) ขึ้นไป
 ขึ้นไป.")
7
สถิตินอนพาราเมตริก (Nonparametric statistics)
คือ อนุมานสถิติในลักษณะที่มีการอ้างอิงค่าสถิติ ซึ่งเป็นค่าที่คำนวณได้จากกลุ่มตัวอย่างกลับไปสู่ค่าพารามิเตอร์ ซึ่งเป็นค่าของกลุ่มประชากร ซึ่งมีข้อตกลงเบื้องต้นดังนี้ - กลุ่มตัวอย่างของข้อมูลไม่มีการแจกแจงเป็นโค้งปกติ - ข้อมูลแต่ละตัวมีความเป็นอิสระต่อกันทั้งภายในกลุ่ม และระหว่างกลุ่ม - ข้อมูลเป็นชนิดนามบัญญัติ (Nominal data) และเรียงอันดับ (Ordinal data)
 และเรียงอันดับ. (Ordinal data)")
8
4. ระดับของความคลาดเคลื่อนที่ยอมให้เกิดขึ้น
ระดับของความคลาดเคลื่อนควรจะเป็นเท่าไรนั้นขึ้นอยู่กับความสำคัญของเรื่องนั้น เช่น การวิจัยเปรียบเทียบผลของยาที่คิดค้นขึ้นใหม่กับยาชนิดเก่า ควรให้ความคลาดเคลื่อนต่ำที่สุดเท่าที่จะเป็นไปได้ เพราะเกี่ยวข้องกับชีวิตของคน แต่ถ้าการวิจัยทางสังคมศาสตร์โดยทั่วไปจะยอมให้มีความ คลาดเคลื่อนได้ 1% หรือ 5 % หรือ 10%

9
5. ขนาดและขอบเขตของประชากร
ถ้าประชากรมีขนาดใหญ่ จำนวนตัวอย่างก็ควรจะมีมากกว่าประชากรที่มีขนาดเล็ก ประชากรขนาดใหญ่ ประชากรขนาดเล็ก

10
6. ข้อจำกัดด้านทรัพยากร
ในทางปฏิบัติการกำหนดขนาดของตัวอย่างส่วนใหญ่ จะต้องพิจารณาถึงปัจจัยเหล่านี้ด้วยเสมอ เช่น งบประมาณ ระยะเวลา และกำลังคน ถ้าต้องการจำนวนตัวอย่างมาก แต่มีงบประมาณหรือกำลังคนน้อยในการเก็บรวบรวมข้อมูลไม่เพียงพอ ก็อาจจะทำให้งานวิจัยนั้นล่าช้าเกินระยะเวลาที่กำหนดไว้ หรืออาจทำให้ไม่สามารถทำงานวิจัยนั้นสำเร็จได้

11
การกำหนดขนาดของตัวอย่าง
การกำหนดขนาดของตัวอย่างมีหลายวิธี โดยพิจารณาจาก ขนาดของกลุ่มตัวอย่างจากประชากรเป้าหมาย กำหนดขนาดตัวอย่างโดยวิธีการทางสถิติ กำหนดขนาดของตัวอย่างโดยใช้ตาราง

12
1. การกำหนดขนาดของตัวอย่างโดยพิจารณาจากขนาดของ ประชากรเป้าหมาย
มีหลักเกณฑ์ในการกำหนดตัวอย่างดังนี้ (นิภา ศรีไพโรจน์ , 2527, หน้า 79) ถ้า < N < ,000 กำหนดให้ n = % ของ N ถ้า , < N < ,000 กำหนดให้ n = % ของ N ถ้า 10, < N < ,000 กำหนดให้ n = % ของ N ถ้า 100, < N < 1,000,000 กำหนดให้ n = % ของ N N หมายถึง จำนวนประชากรทั้งหมด n หมายถึง จำนวนตัวอย่าง
 ถ้า 100 < N < 1,000 กำหนดให้ n = % ของ N. ถ้า 1,000 < N < 10,000 กำหนดให้ n = % ของ N. ถ้า 10,000 < N < 100,000 กำหนดให้ n = % ของ N. ถ้า 100,000 < N < 1,000,000 กำหนดให้ n = % ของ N. N หมายถึง จำนวนประชากรทั้งหมด. n หมายถึง จำนวนตัวอย่าง.")
13
ตัวอย่าง ถ้าจำนวนประชากรมี 500 คน จำนวนตัวอย่างประมาณ 75 - 150 คน
ถ้าจำนวนประชากรมี คน จำนวนตัวอย่างประมาณ คน ถ้าจำนวนประชากรมี 1,800 คน จำนวนตัวอย่างประมาณ คน ถ้าจำนวนประชากรมี 27,500 คน จำนวนตัวอย่างประมาณ 1, ,750 คน ถ้าจำนวนประชากรมี 160,000 คน จำนวนตัวอย่างประมาณ 1, ,800 คน

14
2. กำหนดขนาดของตัวอย่างโดยวิธีการทางสถิติ ๆ
2. กำหนดขนาดของตัวอย่างโดยวิธีการทางสถิติ ๆ ก่อนอื่นจะต้องพิจารณาว่าทราบจำนวนประชากรทั้งหมดหรือไม่ เพราะการคำนวณหาขนาดของประชากร ในกรณีทราบจำนวนประชากร กับ กรณีไม่ทราบจำนวนประชากรจะใช้สูตรต่างกัน

15
สิ่งที่ต้องพิจารณา…... ในการกำหนดขนาดตัวอย่างโดยวิธีการทางสถิติ
1. ค่าความคลาดเคลื่อนจากการประมาณค่า (Standard error of the estimate) : e 2. ระดับความเชื่อมั่น (Level of confidence) : หาจากค่า Z ค่า Z ที่ระดับความเชื่อมั่น 99 % = 2.58 ค่า Z ที่ระดับความเชื่อมั่น 95 % = 1.96 ค่า Z ที่ระดับความเชื่อมั่น 90 % = 1.64
 : e. 2. ระดับความเชื่อมั่น. (Level of confidence) : หาจากค่า Z. ค่า Z ที่ระดับความเชื่อมั่น 99 % = ค่า Z ที่ระดับความเชื่อมั่น 95 % = ค่า Z ที่ระดับความเชื่อมั่น 90 % =")
16
e2 n = Z 2 2 เมื่อ n = จำนวนตัวอย่าง
1. การกำหนดขนาดตัวอย่าง เมื่อต้องการประมาณค่าเฉลี่ย 1.1 เมื่อทราบค่าความแปรปรวน และไม่ทราบขนาดประชากร n = Z 2 2 e2 เมื่อ n = จำนวนตัวอย่าง Z = คะแนนมาตรฐาน 2 = ความแปรปรวนของประชากร e = ค่าความคลาดเคลื่อนจากการประมาณค่า

17
e2 n = Z2 2 e = 10 % ของ 10,000 = 1,000 ตัวอย่างที่ 1 = 10,000 = 4,000
ตัวอย่างที่ 1 ในการสำรวจรายได้เฉลี่ยของประชากรในหมู่บ้านแห่งหนึ่ง พบว่าประชากรในหมู่บ้านนี้มีรายได้เฉลี่ย 10,000 บาท ค่าเบี่ยงเบนมาตรฐานของรายได้เท่ากับ 4,000 บาท ผู้วิจัยควรจะใช้จำนวนตัวอย่างเท่าไรจึงจะทำให้รายได้เฉลี่ยที่ได้จากการสำรวจด้วยตัวอบ่างคลาดเคลื่อนเพียง 10% ของรายได้เฉลี่ยของประชากร โดยกำหนดระดับความเชื่อมั่นในการประมาณค่า 95% e = 10 % ของ 10, = 1,000 = 10,000 = 4,000 ค่า Z ที่ระดับความเชื่อมั่น 95 % = n = Z2 = (1.96)2 (4,000)2 = คน 2 e2 (1,000)2
2 (4,000)2. = 61 คน. 2. e2. (1,000)2.")
18
Ne2 + Z2 n = NZ2 2 2 เมื่อ n = จำนวนตัวอย่าง N = จำนวนประชากร
1.2 เมื่อทราบค่าความแปรปรวน และทราบขนาดประชากร n = NZ2 2 Ne2 + Z2 2 เมื่อ n = จำนวนตัวอย่าง N = จำนวนประชากร Z = ค่ามาตรฐานที่ระดับความเชื่อมั่นตามที่กำหนด e = ค่าความคลาดเคลื่อนจากการประมาณค่า

19
ตัวอย่างที่ 2 จากตัวอย่างที่ 1 ถ้าทราบว่าประชากรทั้งหมดของจังหวัดนั้นเท่ากับ 3,760,533 คน ผู้วิจัยจะต้องใช้ขนาดตัวอย่างเท่าใด n = N Z2 2 2 Ne2 + Z2 (3,760,533) (1.96)2 (4,000)2 (3,760,533) (1,000)2 +(1.96)2 (4,000)2 = คน
 (1.96)2 (4,000)2. (3,760,533) (1,000)2 +(1.96)2 (4,000)2. = คน.")
20
1.3 เมื่อไม่ทราบค่าความแปรปรวน และไม่ทราบขนาดประชากร
n = e2 Z2 (est. )2 ค่าความแปรปรวน ? ขนาด ประชากร ?
2. ค่าความแปรปรวน ขนาด. ประชากร")
21
e2 n = Z2 2 e = 5 % ของ 7,000 = 350 ตัวอย่างที่ 3 = 7,000
ตัวอย่างที่ 3 การศึกษาค่าใช้จ่ายโดยเฉลี่ยของนักท่องเที่ยวในปี พ.ศ สมมติจากข้อมูลที่มีอยู่พบว่าค่าใช้จ่ายโดยเฉลี่ยของนักท่องเที่ยวประมาณคนละ 7,000บาท และค่าเบี่ยงเบนมาตรฐานของค่าใช้จ่ายที่คำนวณได้จากการทำ Pilot Study (est. หรือ standard deviation) เท่ากับ 2,250 บาท ถ้าผู้วิจัยต้องการค่าความคลาดเคลื่อนเท่ากับ 5% ของค่าเฉลี่ยของค่าใช้จ่ายและระดับความเชื่อมั่นที่ 95 % ผู้วิจัยจะต้องใช้ขนาดตัวอย่างเท่าใด e = 5 % ของ 7, = 350 = 7,000 est. = 2,250 ค่า Z ที่ระดับความเชื่อมั่น 95 % = 1.96 n = Z2 2 (est. ) = (1.96)2 (2,250)2 = คน e2 (350)2
 เท่ากับ 2,250 บาท ถ้าผู้วิจัยต้องการค่าความคลาดเคลื่อนเท่ากับ 5% ของค่าเฉลี่ยของค่าใช้จ่ายและระดับความเชื่อมั่นที่ 95 % ผู้วิจัยจะต้องใช้ขนาดตัวอย่างเท่าใด. e = 5 % ของ 7,000 = 350. = 7,000. est. = 2,250. ค่า Z ที่ระดับความเชื่อมั่น 95 % = n = Z2. 2. (est. ) = (1.96)2 (2,250)2. = คน. e2. (350)2.")
22
1.4 เมื่อไม่ทราบค่าความแปรปรวน และทราบขนาดประชากร
n0 n = n0 1 + N Z2 (est. )2 เมื่อ n0 = e2
2. เมื่อ. n0 = e2.")
23
e2 n0 n = n0 n0 = Z2 2 n = N = 159 คน ตัวอย่างที่ 4 1 +
ตัวอย่างที่ 4 จากตัวอย่างที่ 3 ถ้าทราบขนาดประชากรนักท่องเที่ยวในปี พ.ศ เท่ากับ 100,000 คน ผู้วิจัยจะต้องใช้ขนาดตัวอย่างเท่าใด n0 n = n0 1 + N n0 = Z2 (est. ) = (1.96)2 (2,250)2 2 = คน e2 (350)2 159 n = = คน 159 1 + 100,000
 = (1.96)2 (2,250)2. 2. = 159 คน. e2. (350) n = = 159 คน ,000.")
24
e2 n = Z2 p (1-p) เมื่อ n = จำนวนตัวอย่าง p
2. การกำหนดขนาดตัวอย่าง เมื่อต้องการประมาณค่าสัดส่วน 2.1 เมื่อทราบค่าสัดส่วน และไม่ทราบขนาดประชากร n = Z2 p (1-p) e2 เมื่อ n = จำนวนตัวอย่าง Z = คะแนนมาตรฐาน p = สัดส่วนของลักษณะที่สนใจในประชากร e = ค่าความคลาดเคลื่อนจากการประมาณค่า
 e2. เมื่อ n = จำนวนตัวอย่าง. Z = คะแนนมาตรฐาน. p. = สัดส่วนของลักษณะที่สนใจในประชากร. e = ค่าความคลาดเคลื่อนจากการประมาณค่า.")
25
2.2 เมื่อทราบค่าสัดส่วน และทราบขนาดประชากร
n0 n = n0 1 + N n0 = Z2 p (1-p) เมื่อ e2
 เมื่อ. e2.")
26
2.3 เมื่อไม่ทราบค่าสัดส่วน และไม่ทราบขนาดประชากร
n = Z2 p (1-p) e2 = Z2 0.5 ( ) e2 n = Z2 4e2
 e2. = Z ( ) e2. n = Z2. 4e2.")
27
2.4 เมื่อไม่ทราบค่าสัดส่วน และทราบขนาดประชากร
n = N Z2 p (1 - p) Ne2 + Z2 p (1 - p)
 Ne2 + Z2. p (1 - p)")
28
3. การกำหนดขนาดของตัวอย่างโดยใช้ตาราง
กรณีทราบจำนวนประชากร และต้องการคำนวณขนาดของตัวอย่างที่ใช้ในการสำรวจ เพื่อนำไปประมาณค่าเฉลี่ยของประชากร ใช้สูตรดังนี้ N (CV)2 Z2 n = (CV)2 Z2 + (N-1) e2 เมื่อ n = จำนวนตัวอย่าง N = จำนวนประชากร Z = คะแนนมาตรฐานที่ระดับความเชื่อมั่นตามที่กำหนด CV = สัมประสิทธิ์ความผันแปร e = ค่าความคลาดเคลื่อนจากการประมาณค่า
2 Z2. n = (CV)2 Z2 + (N-1) e2. เมื่อ n = จำนวนตัวอย่าง. N = จำนวนประชากร. Z = คะแนนมาตรฐานที่ระดับความเชื่อมั่นตามที่กำหนด. CV = สัมประสิทธิ์ความผันแปร. e = ค่าความคลาดเคลื่อนจากการประมาณค่า.")
29
N (CV)2 Z2 n = N n = จากค่า Z ค่า Z ที่ระดับความเชื่อมั่น 99 % = 2.58
3 ค่า Z ที่ระดับความเชื่อมั่น 95 % = 1.96 2 ค่า Z ที่ระดับความเชื่อมั่น 90 % = 1.64 N (CV)2 Z2 n = (CV)2 Z2 + (N-1) e2 เมื่อ N มีค่าใหญ่มาก N - 1 จะมีค่าใกล้เคียง N N n = 1 + Ne2
2 Z2. n = (CV)2 Z2 + (N-1) e2. เมื่อ N มีค่าใหญ่มาก N - 1 จะมีค่าใกล้เคียง N. N. n = 1 + Ne2.")
30
ตารางสำเร็จที่ใช้สูตรของ Taro Yamane

31
วิธีการสุ่มตัวอย่าง 1. วิธีการสุ่มตัวอย่างแบบไม่ใช้ความน่าจะเป็น
(Non Probability Sampling) 2. วิธีการสุ่มตัวอย่างแบบใช้ความน่าจะเป็น (Probability Sampling)
 2. วิธีการสุ่มตัวอย่างแบบใช้ความน่าจะเป็น. (Probability Sampling)")
32
1. วิธีการสุ่มตัวอย่างแบบไม่ใช้ความน่าจะเป็น
(Non Probability Sampling) การสุ่มตัวอย่างโดยไม่ทราบโอกาสที่หน่วยต่าง ๆ ของประชากรจะถูกสุ่มไปเป็นกลุ่มตัวอย่าง การสุ่มแบบนี้ ผู้วิจัยไม่สามารถคาดเดาหรือประมาณได้ว่า โอกาสที่แต่ละหน่วยของประชากรเป้าหมายจะถูกสุ่มมาเป็นตัวอย่างเท่ากับเท่าไร วิธีนี้แบ่งได้ 4 แบบ คือ
 การสุ่มตัวอย่างโดยไม่ทราบโอกาสที่หน่วยต่าง ๆ ของประชากรจะถูกสุ่มไปเป็นกลุ่มตัวอย่าง การสุ่มแบบนี้ ผู้วิจัยไม่สามารถคาดเดาหรือประมาณได้ว่า โอกาสที่แต่ละหน่วยของประชากรเป้าหมายจะถูกสุ่มมาเป็นตัวอย่างเท่ากับเท่าไร วิธีนี้แบ่งได้ 4 แบบ คือ.")
33
(การสุ่มตัวอย่างแบบตามความสะดวกหรือแบบบังเอิญ)
1.1 Convenience or Accidental Sampling (การสุ่มตัวอย่างแบบตามความสะดวกหรือแบบบังเอิญ) เป็นการสุ่มตัวอย่างที่อาศัยความสะดวกในการเก็บรวบรวมข้อมูลหรือสุ่มตัวอย่างโดยบังเอิญหรือไม่ได้ตั้งใจ ตัวอย่างที่ ได้จากการสุ่มตัวอย่างแบบนี้ จะไม่สามารถนำไปเป็นตัวแทนของประชากรได้ เพราะไม่ได้มีการควบคุมการสุ่มตัวอย่างให้เป็นไปอย่างสุ่ม จึงอาจเกิดความลำเอียงในการเลือกตัวอย่างขึ้นได้ ดังนั้นผู้ที่จะนำผลการวิจัยที่ใช้วิธีการสุ่มตัวอย่างแบบนี้ไปใช้ ควรจะตระหนักถึงความน่าเชื่อถือของการสุ่มตัวอย่างด้วย
 เป็นการสุ่มตัวอย่างที่อาศัยความสะดวกในการเก็บรวบรวมข้อมูลหรือสุ่มตัวอย่างโดยบังเอิญหรือไม่ได้ตั้งใจ ตัวอย่างที่ ได้จากการสุ่มตัวอย่างแบบนี้ จะไม่สามารถนำไปเป็นตัวแทนของประชากรได้ เพราะไม่ได้มีการควบคุมการสุ่มตัวอย่างให้เป็นไปอย่างสุ่ม จึงอาจเกิดความลำเอียงในการเลือกตัวอย่างขึ้นได้ ดังนั้นผู้ที่จะนำผลการวิจัยที่ใช้วิธีการสุ่มตัวอย่างแบบนี้ไปใช้ ควรจะตระหนักถึงความน่าเชื่อถือของการสุ่มตัวอย่างด้วย.")
34
ตัวอย่าง เช่น ผู้เก็บข้อมูลอาจจะขอความร่วมมือจากผู้ที่อยู่ในเหตุการณ์หรือสถานที่นั้น เช่น ศูนย์การค้า ธนาคาร มหาวิทยาลัย โรงเรียน สวนสนุก ที่จอดรถโดยสารประจำทาง ถนน โรงพยาบาล ฯลฯ เป็นต้น ผู้ที่ให้ความร่วมมือตอบคำถามก็จะเป็นหน่วยตัวอย่าง (Sampling element) การเก็บข้อมูลตามสะดวกเช่นนี้ถึงแม้ว่ากลุ่มตัวอย่างจะมีขนาดใหญ่สักแค่ไหนก็ตาม ก็ไม่ถือว่ากลุ่มตัวอย่างนั้นเป็นตัวแทนที่ดีของประชากร ผู้ที่ตอบแบบสอบถามหรือผู้ให้สัมภาษณ์ คือ คนที่ “บังเอิญ” อยู่ในเหตุการณ์นั้น ๆ และยินดีให้ข้อมูล ดังนั้นนักวิจัยจะไม่ทราบว่าความน่าจะเป็นหรือโอกาสที่หน่วยตัวอย่างนั้นถูกเลือกขึ้นมาจากประชากรมีค่าเป็นเท่าใด เมื่อเป็นเช่นนี้ นักวิจัยย่อมไม่ทราบว่าความคลาดเคลื่อนจากการเลือกตัวอย่าง (Sampling error) จะเป็นเท่าไรด้วย
 การเก็บข้อมูลตามสะดวกเช่นนี้ถึงแม้ว่ากลุ่มตัวอย่างจะมีขนาดใหญ่สักแค่ไหนก็ตาม ก็ไม่ถือว่ากลุ่มตัวอย่างนั้นเป็นตัวแทนที่ดีของประชากร ผู้ที่ตอบแบบสอบถามหรือผู้ให้สัมภาษณ์ คือ คนที่ บังเอิญ อยู่ในเหตุการณ์นั้น ๆ และยินดีให้ข้อมูล ดังนั้นนักวิจัยจะไม่ทราบว่าความน่าจะเป็นหรือโอกาสที่หน่วยตัวอย่างนั้นถูกเลือกขึ้นมาจากประชากรมีค่าเป็นเท่าใด เมื่อเป็นเช่นนี้ นักวิจัยย่อมไม่ทราบว่าความคลาดเคลื่อนจากการเลือกตัวอย่าง (Sampling error) จะเป็นเท่าไรด้วย.")
35
นักวิจัยส่วนใหญ่ใช้วิธีการเลือกตัวอย่างตามสะดวกในการทำวิจัยเป็นส่วนมาก เพราะความง่ายไม่ยุ่งยากในการดำเนินการ เหตุผลอีกประการหนึ่ง ก็คือ ลักษณะการวิจัยที่เป็นการวิจัยแบบสืบเสาะอนุโลมให้ใช้การเลือกตัวอย่างแบบสะดวกได้ในการทำวิจัยประเภทนี้

36
การวิจัยแบบสืบเสาะ (Exploratory research)
เป็นการวิจัยในรูปแบบของการค้นคว้า เพื่อให้ได้มาซึ่งความเข้าใจในปัญหาหรือเพื่อให้ได้มาซึ่งความคิดใหม่ ๆ การวิจัยแบบนี้มีประโยชน์อย่างมาก ในการที่แยกแยะปัญหาใหญ่ของการทำวิจัยออกเป็นปัญหาย่อยที่เฉพาะเจาะจงมากขึ้น ปัญหาย่อย ๆ นี้จะใช้เป็นพื้นฐานในการกำหนดสมมติฐาน (hypothesis) ของการทำวิจัย ตัวอย่าง เช่น ปัญหายอดขายตกต่ำ สาเหตุของยอดขายต่ำอาจมีอยู่หลายสาเหตุด้วนกัน เช่น ตั้งราคาสูงเกินไป การโฆษณาประชาสัมพันธ์ไม่ได้ผล หรือการให้บริการของพนักงานไม่เป็นที่ประทับใจลูกค้า ฯลฯ
 ของการทำวิจัย ตัวอย่าง เช่น ปัญหายอดขายตกต่ำ สาเหตุของยอดขายต่ำอาจมีอยู่หลายสาเหตุด้วนกัน เช่น ตั้งราคาสูงเกินไป การโฆษณาประชาสัมพันธ์ไม่ได้ผล หรือการให้บริการของพนักงานไม่เป็นที่ประทับใจลูกค้า ฯลฯ.")
37
1.2 Purposive Sampling (การสุ่มตัวอย่างแบบเจาะจง) เป็นการสุ่มตัวอย่างที่ผู้วิจัยต้องใช้วิจารณญาณ หรือใช้ประสบการณ์ในการเจาะจงสุ่มหน่วยตัวอย่างนั้น ๆ มาศึกษาการสุ่มตัวอย่างแบบนี้ ผู้วิจัยควรเป็นผู้ที่คุ้นเคย กับลักษณะต่าง ๆ ของประชากรเป้าหมายเป็นอย่างดี จึงจะตัดสินใจได้ว่าควรสุ่มตัวอย่างที่มีลักษณะเช่นใดมาศึกษา

38
ตัวอย่าง เช่น การทดสอบตลาด ( Marketing test ) สำหรับการออกผลิตภัณฑ์ใหม่ ผู้ทำวิจัยพิจารณาว่าจะทดสอบที่จังหวัดใด จึงจะได้ผลมากที่สุด เขาอาจจะเลือกจังหวัดเชียงใหม่ ขอนแก่น สุพรรณบุรี ภูเก็ต สำหรับการทดสอบตลาด เพราะเป็นจังหวัดใหญ่ที่เป็นศูนย์กลางของแต่ละภูมิภาคในประเทศไทย การเลือกตัวอย่างโดยวิธีนี้มีข้อดีที่เหนือกว่าการเลือกตัวอย่างตามสะดวก คือ อย่างน้อยผู้วิจัยก็ยังใช้วิจารณญาณในการเลือกตัวอย่าง ถ้าหากว่าวิจารณญาณนั้นถูกต้อง ข้อมูลที่ได้รับมาก็จะมีความเชื่อถือได้ในระดับหนึ่ง

39
(การสุ่มตัวอย่างแบบกำหนดจำนวนตัวอย่าง)
1.3 Quota Sampling (การสุ่มตัวอย่างแบบกำหนดจำนวนตัวอย่าง) เป็นการสุ่มตัวอย่างแบบกำหนดจำนวนตัวอย่างที่มีคุณลักษณะบางประการไว้ก่อนที่จะทำการสุ่มตัวอย่าง การสุ่มตัวอย่างจะเลือกตามสัดส่วนของประชากรที่เราทราบจำนวน เช่น ข้อมูลนักศึกษาของสถาบันการศึกษาแห่งหนึ่ง มีนักศึกษาชาย 8,500 คน และนักศึกษาหญิง 7,000 คน ดังนั้นสัดส่วนระหว่างนักศึกษาชายและนักศึกษาหญิง คือ 85 : และการวิจัยนี้เก็บตัวอย่างมา 10 % ของนักศึกษาทั้งหมดตามสัดส่วนของนักศึกษาชายและหญิง เพราะฉะนั้นจะได้กลุ่มตัวอย่างนักศึกษาชาย คน และนักศึกษาหญิง คน รวมเป็นจำนวนตัวอย่างทั้งสิ้น 1,570 คน
 เป็นการสุ่มตัวอย่างแบบกำหนดจำนวนตัวอย่างที่มีคุณลักษณะบางประการไว้ก่อนที่จะทำการสุ่มตัวอย่าง การสุ่มตัวอย่างจะเลือกตามสัดส่วนของประชากรที่เราทราบจำนวน เช่น. ข้อมูลนักศึกษาของสถาบันการศึกษาแห่งหนึ่ง มีนักศึกษาชาย 8,500 คน และนักศึกษาหญิง 7,000 คน ดังนั้นสัดส่วนระหว่างนักศึกษาชายและนักศึกษาหญิง คือ 85 : 72 และการวิจัยนี้เก็บตัวอย่างมา 10 % ของนักศึกษาทั้งหมดตามสัดส่วนของนักศึกษาชายและหญิง เพราะฉะนั้นจะได้กลุ่มตัวอย่างนักศึกษาชาย 850 คน และนักศึกษาหญิง 720 คน รวมเป็นจำนวนตัวอย่างทั้งสิ้น 1,570 คน.")
40
1.4 Snowball sampling (การสุ่มตัวอย่างแบบลูกหิมะ) เป็นการสุ่มตัวอย่างแบบนี้เหมาะกับประชากรที่ไม่มีการเปิดเผยรายชื่ออย่างเป็นทางการ หรือเป็นประชากรกลุ่มพิเศษที่ไม่ปรากฏอยู่ทั่วไป หรือมีที่อยู่ไม่แน่นอน เช่น เด็กเร่ร่อนที่ติดยา หญิงบริการที่เป็นโสเภณี

41
2. วิธีการสุ่มตัวอย่างแบบใช้ความน่าจะเป็น
(Probability Sampling) การสุ่มตัวอย่างโดยทราบโอกาสที่หน่วยต่างๆ ของประชากรเป้าหมายจะถูกสุ่มมาเป็นหน่วยตัวอย่าง ถ้าใช้วิธีการสุ่มตัวอย่างแบบนี้ได้อย่างถูกต้อง ผู้วิจัยสามารถกล่าวได้ว่า กลุ่มตัวอย่างที่สุ่ม (random sample) มาเป็น ตัวแทนของประชากร
 การสุ่มตัวอย่างโดยทราบโอกาสที่หน่วยต่างๆ ของประชากรเป้าหมายจะถูกสุ่มมาเป็นหน่วยตัวอย่าง ถ้าใช้วิธีการสุ่มตัวอย่างแบบนี้ได้อย่างถูกต้อง ผู้วิจัยสามารถกล่าวได้ว่า. กลุ่มตัวอย่างที่สุ่ม (random sample) มาเป็น... ตัวแทนของประชากร.")
42
ตัวอย่างสุ่ม (Random Sample)
วิธีการสุ่มแบบนี้ใช้ในกรณีที่ประชากรมีขนาดใหญ่ (จำนวนมาก) ใช้วิธีการสุ่มตัวอย่างแบบสุ่ม (Randomization) เพื่อให้ลักษณะของหน่วยต่าง ๆ ที่สุ่มมานั้นเหมือนกับลักษณะของประชากรมากที่สุด เรียกว่า ตัวอย่างสุ่ม (Random Sample)
 ใช้วิธีการสุ่มตัวอย่างแบบสุ่ม (Randomization) เพื่อให้ลักษณะของหน่วยต่าง ๆ ที่สุ่มมานั้นเหมือนกับลักษณะของประชากรมากที่สุด. เรียกว่า. ตัวอย่างสุ่ม (Random Sample)")
43
การสุ่มตัวอย่างแบบสุ่ม แบ่งได้ 5 วิธี
การสุ่มตัวอย่างแบบสุ่ม แบ่งได้ 5 วิธี 2.1 Simple Random Sampling 2.2 Systematic Random Sampling 2.3 Cluster Random Sampling 2.5 Multi Stage Cluster Sampling 2.4 Stratified Random Sampling

44
ข้อควรระวัง (การสุ่มตัวอย่างแบบง่าย)
2.1 Simple Random Sampling (การสุ่มตัวอย่างแบบง่าย) การสุ่มตัวอย่างแบบนี้เหมาะสมกับประชากรที่มีขนาดเล็ก และมีกรอบของการสุ่มตัวอย่าง (Sampling Frame) ที่สมบูรณ์ ข้อควรระวัง เพราะถ้าประชากรมีขนาดใหญ่มากจะทำให้เสียเวลาในการทำกรอบของการสุ่มตัวอย่าง และเสียเวลาในการสุ่มตัวอย่างมาก นอกจากนี้หน่วยต่าง ๆ ของประชากร จะต้องมีความเป็นเอกพันธ์ (Homogenous) หรือประกอบด้วยหน่วยตัวอย่างที่เหมือนๆ กัน และสถานที่อยู่ของหน่วยต่าง ๆ ของประชากร ไม่กระจัดกระจายกันมาก
 การสุ่มตัวอย่างแบบนี้เหมาะสมกับประชากรที่มีขนาดเล็ก และมีกรอบของการสุ่มตัวอย่าง (Sampling Frame) ที่สมบูรณ์ ข้อควรระวัง. เพราะถ้าประชากรมีขนาดใหญ่มากจะทำให้เสียเวลาในการทำกรอบของการสุ่มตัวอย่าง และเสียเวลาในการสุ่มตัวอย่างมาก. นอกจากนี้หน่วยต่าง ๆ ของประชากร จะต้องมีความเป็นเอกพันธ์ (Homogenous) หรือประกอบด้วยหน่วยตัวอย่างที่เหมือนๆ กัน และสถานที่อยู่ของหน่วยต่าง ๆ ของประชากร ไม่กระจัดกระจายกันมาก.")
45
เพราะถ้าหน่วยต่าง ๆ ของประชากรอยู่กระจัดกระจาย หรือ มีที่อยู่ห่างไกลกันมาก การสุ่มตัวอย่างแบบนี้จะไม่สะดวกในการเก็บรวบรวมข้อมูล

46
ขั้นตอนการสุ่มตัวอย่างแบบง่าย มีดังนี้
ขั้นตอนการสุ่มตัวอย่างแบบง่าย มีดังนี้ ขั้นตอนที่ 1 สร้างกรอบของการสุ่มตัวอย่าง ขั้นตอนที่ 2 กำหนดหรือคำนวณหาจำนวนตัวอย่าง ที่เหมาะสมกับขนาดของประชากร ขั้นตอนที่ 3 สุ่มหน่วยตัวอย่างแบบง่าย ซึ่งมีอยู่ด้วยกัน หลายวิธี เช่น

47
ก. วิธีจับฉลาก (The Lottery Method)
การสุ่มตัวอย่างวิธีนี้ผู้วิจัยจะต้องทำสลากขึ้นมา โดยเขียนตั้งแต่หมายเลขแรกไปจนหมายเลขสุดท้าย (ไม่เขียนหมายเลขซ้ำ) แล้วนำ ไปใส่กล่องจากนั้นหยิบสลากขึ้นมาอย่างสุ่ม วิธีการหยิบอาจทำได้ 3 แบบ 1. หยิบสลากครั้งละใบ แล้วใส่กลับคืนที่เดิม 2. หยิบสลากครั้งเดียวจนครบตามจำนวนที่ต้องการ ครบตามจำนวนที่กำหนด 3. หยิบสลากคืนมาทีละใบ โดยไม่ใส่คืนที่จนกว่าจะได้
 แล้วนำ ไปใส่กล่องจากนั้นหยิบสลากขึ้นมาอย่างสุ่ม. วิธีการหยิบอาจทำได้ 3 แบบ. 1. หยิบสลากครั้งละใบ แล้วใส่กลับคืนที่เดิม. 2. หยิบสลากครั้งเดียวจนครบตามจำนวนที่ต้องการ. ครบตามจำนวนที่กำหนด. 3. หยิบสลากคืนมาทีละใบ โดยไม่ใส่คืนที่จนกว่าจะได้")
48
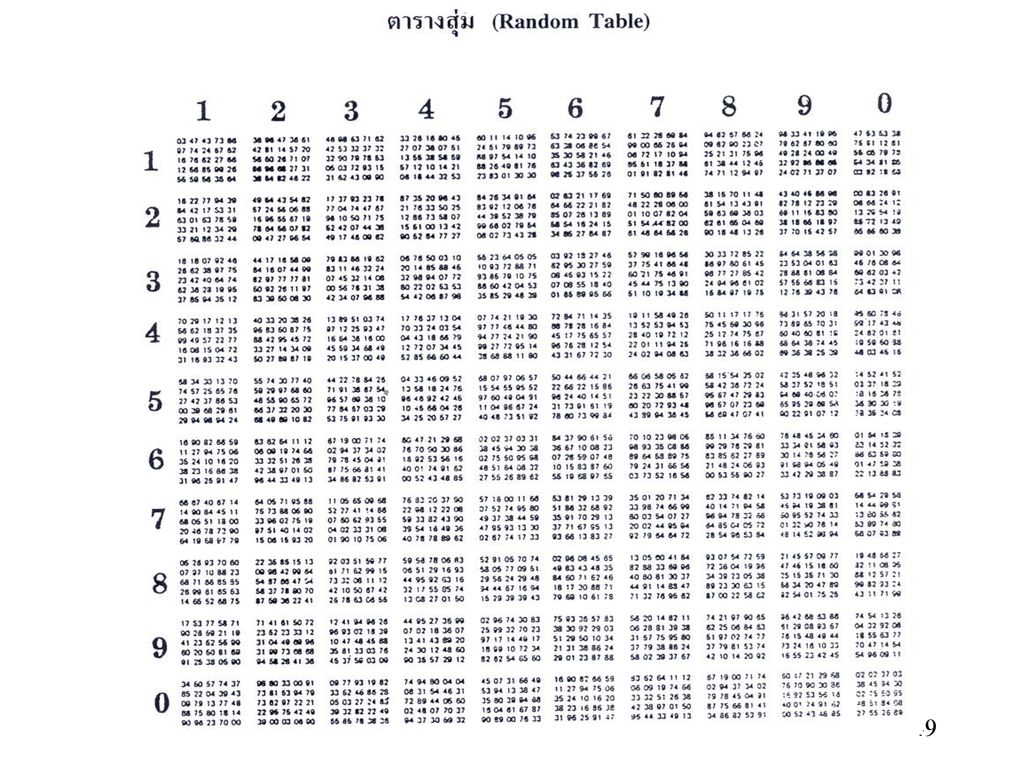
ข. วิธีใช้ตารางเลขสุ่ม
ข. วิธีใช้ตารางเลขสุ่ม (The Table of Random Numbers Method) การสุ่มตัวอย่างแบบนี้เป็นที่นิยมมาก เพราะผู้วิจัยไม่ต้องเสียเวลาทำวงล้อหรือทำสลาก ผู้วิจัยเพียงแต่เปิดตารางสุ่มซึ่งมีอยู่ในหนังสือสถิติทั่วๆ ไป ตารางเลขสุ่มจะประกอบไปด้วยแนวนอน 10 แถบ (Block) และแนวตั้ง 10 แถบ (Block) ภายในแถบต่าง ๆ จะประกอบตัวเลข 2 หลักเรียงกัน
 การสุ่มตัวอย่างแบบนี้เป็นที่นิยมมาก เพราะผู้วิจัยไม่ต้องเสียเวลาทำวงล้อหรือทำสลาก ผู้วิจัยเพียงแต่เปิดตารางสุ่มซึ่งมีอยู่ในหนังสือสถิติทั่วๆ ไป ตารางเลขสุ่มจะประกอบไปด้วยแนวนอน 10 แถบ (Block) และแนวตั้ง 10 แถบ (Block) ภายในแถบต่าง ๆ จะประกอบตัวเลข 2 หลักเรียงกัน.")
50
ตัวอย่างแสดงหมายเลขการสุ่มตัวอย่างแบบง่าย
(Simple Random Sampling) (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) (30) (31) (32) (33) (34) (35) ประชากร (18) (13) (24) (2) (16) (11) (35) (12) กลุ่มตัวอย่าง
 (1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) (30) (31) (32) (33) (34) (35) ประชากร. (18) (13) (24) (2) (16) (11) (35) (12) กลุ่มตัวอย่าง.")
51
ข้อดีของการสุ่มตัวอย่างแบบง่าย
การสุ่มตัวอย่างแบบง่าย เป็นวิธีที่ได้รับความนิยมอย่างมาก เพราะเป็นการสุ่มตัวอย่างมีหลักเกณฑ์ สามารถให้ผลการวิจัยที่เชื่อถือได้และไม่ยุ่งยากในการปฏิบัติ หน่วยตัวอย่างทุกหน่วยมีโอกาสถูกเลือกเท่าเทียมกันหมด

52
2.2 Systematic Random Sampling
(การสุ่มตัวอย่างอย่างเป็นระบบ) การสุ่มตัวอย่างโดยวิธีนี้ช่วย ประหยัดเวลา ในการสุ่มตัวอย่างควรใช้วิธีการสุ่มตัวอย่างแบบนี้กับประชากรที่มีขนาดเล็กและ มีกรอบของการสุ่มตัวอย่างที่สมบูรณ์ และหน่วยต่าง ๆ ของประชากรไม่อยู่กระจัดกระจายกันมาก การสุ่มตัวอย่างแบบเป็นระบบมีขั้นตอน ดังนี้ คือ ขั้นตอนที่ 1 สร้างกรอบของการสุ่มตัวอย่าง ขั้นตอนที่ 2 กำหนดหรือคำนวณหาจำนวนตัวอย่างที่เหมาะสม ขั้นตอนที่ 3 คำนวณหาช่วงของการสุ่มตัวอย่าง (Sampling Interval หรือ I )
 การสุ่มตัวอย่างโดยวิธีนี้ช่วย ประหยัดเวลา ในการสุ่มตัวอย่างควรใช้วิธีการสุ่มตัวอย่างแบบนี้กับประชากรที่มีขนาดเล็กและ มีกรอบของการสุ่มตัวอย่างที่สมบูรณ์ และหน่วยต่าง ๆ ของประชากรไม่อยู่กระจัดกระจายกันมาก. การสุ่มตัวอย่างแบบเป็นระบบมีขั้นตอน ดังนี้ คือ. ขั้นตอนที่ 1 สร้างกรอบของการสุ่มตัวอย่าง. ขั้นตอนที่ 2 กำหนดหรือคำนวณหาจำนวนตัวอย่างที่เหมาะสม. ขั้นตอนที่ 3 คำนวณหาช่วงของการสุ่มตัวอย่าง. (Sampling Interval หรือ I )")
53
n ตัวอย่าง เช่น 6 โดยที่ I = N (ใช้ค่าจำนวนเต็ม)
มีประชากรทั้งหมด 50 หน่วย ต้องการสุ่มตัวอย่างมา 6 หน่วย ดังนั้น ช่วงของการเลือกตัวอย่าง (i) = = 6
 = 50 =")
54
ขั้นตอนที่ 4 สุ่มหมายเลขเริ่มต้น ( Random Start ) หรือ R โดย
การสุ่มหมายเลข 1 ถึง i ขึ้นมา 1 หน่วย ด้วยวิธีการสุ่มแบบง่าย เช่น จากการสุ่มหมายเลข ด้วยวิธีการจับฉลากได้หมายเลข 4 ดังนั้นหน่วยของประชากร หมายเลข 4 จะเป็นหน่วยตัวอย่างเริ่มต้น (R = 4) ขั้นตอนที่ 5 เลือกสมาชิกหมายเลขต่อไป โดยจะเลือกหมายเลข ต่อ ๆ ไปตามลำดับ ดังนี้ R + i , R + 2 i ,… , R + (n - 1) i ในขั้นที่ 5 เราจะได้หน่วยตัวอย่างที่มีหมายเลขประจำตัวดังนี้ 4 , 12 , 20 , 28 , 36 , 44
 ขั้นตอนที่ 5 เลือกสมาชิกหมายเลขต่อไป โดยจะเลือกหมายเลข. ต่อ ๆ ไปตามลำดับ ดังนี้ R + i , R + 2 i ,… , R + (n - 1) i ในขั้นที่ 5 เราจะได้หน่วยตัวอย่างที่มีหมายเลขประจำตัวดังนี้ 4 , 12 , 20 , 28 , 36 , 44.")
55
แผนผังแสดงการสุ่มตัวอย่างแบบเป็นระบบ (Systematic Sampling)
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) (30) (31) (32) (33) (34) (35) (36) (37) (38) (39) (40) (41) (42) (43) (44) (45) (46) (47) (48) (49) (50) ประชากร สุ่มหน่วยตัวอย่างแบบเป็นระบบ (4) (12) (20) (28) (36) (44) กลุ่มตัวอย่าง
 (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13) (14) (15) (16) (17) (18) (19) (20) (21) (22) (23) (24) (25) (26) (27) (28) (29) (30) (31) (32) (33) (34) (35) (36) (37) (38) (39) (40) (41) (42) (43) (44) (45) (46) (47) (48) (49) (50) ประชากร. สุ่มหน่วยตัวอย่างแบบเป็นระบบ. (4) (12) (20) (28) (36) (44) กลุ่มตัวอย่าง.")
56
ข้อดีของการสุ่มตัวอย่างแบบเป็นระบบ
การสุ่มตัวอย่างแบบเป็นระบบ จะให้ผลดีกว่าการสุ่มตัวอย่างแบบง่าย เนื่องจากมีความคลาดเคลื่อนของการเลือกตัวอย่างน้อยกว่า และผู้วิจัยไม่จำเป็นต้องมีความรู้มากนักเกี่ยวกับคุณลักษณะของกรอบตัวอย่าง เช่น สัมภาษณ์ผู้ที่เดินออกมาจากห้างสรรพสินค้าทุกคนที่ 10 โดยไม่สนใจว่าเป็นใคร ข้อดีอีกประการหนึ่ง คือ ช่วยประหยัดค่าใช้จ่ายได้มากกว่าการสุ่มตัวอย่างอย่างง่าย เพราะมีการสุ่มหมายเลขเริ่มต้นเพียงครั้งเดียว นิยมใช้ในการสัมภาษณ์ทางโทรศัพท์ และสอบถามผู้คนในร้านค้า

57
(การสุ่มตัวอย่างแบบกลุ่ม)
2.3 Cluster Random Sampling (การสุ่มตัวอย่างแบบกลุ่ม) การสุ่มตัวอย่างวิธีนี้เหมาะกับประชากรที่แบ่งออกเป็นกลุ่มๆ โดยที่แต่ละกลุ่มมีความคล้ายคลึงกัน และหน่วยต่างๆ ที่อยู่ภายในกลุ่มมีความแตกต่างกัน ในทางปฏิบัติวิธีการสุ่มแบบนี้เป็นที่นิยมมาก เนื่องจาก ประชากรมีขนาดใหญ่ จึงทำให้ไม่สามารถสร้างกรอบของการสุ่มตัวอย่างที่สมบูรณ์ได้ และถ้าหน่วยต่าง ๆ ของประชากรที่อยู่ห่างไกลกัน หรือ อยู่กระจัดกระจายกันมาก ถ้าใช้วิธีการสุ่มตัวอย่างแบบง่ายจะไม่เหมาะสม เพราะจะทำให้ไม่สะดวกในการเก็บข้อมูล สิ้นเปลืองเวลาและค่าใช้จ่าย
 การสุ่มตัวอย่างวิธีนี้เหมาะกับประชากรที่แบ่งออกเป็นกลุ่มๆ โดยที่แต่ละกลุ่มมีความคล้ายคลึงกัน และหน่วยต่างๆ ที่อยู่ภายในกลุ่มมีความแตกต่างกัน ในทางปฏิบัติวิธีการสุ่มแบบนี้เป็นที่นิยมมาก เนื่องจาก ประชากรมีขนาดใหญ่ จึงทำให้ไม่สามารถสร้างกรอบของการสุ่มตัวอย่างที่สมบูรณ์ได้ และถ้าหน่วยต่าง ๆ ของประชากรที่อยู่ห่างไกลกัน หรือ อยู่กระจัดกระจายกันมาก ถ้าใช้วิธีการสุ่มตัวอย่างแบบง่ายจะไม่เหมาะสม เพราะจะทำให้ไม่สะดวกในการเก็บข้อมูล สิ้นเปลืองเวลาและค่าใช้จ่าย.")
58
การสุ่มแบบกลุ่มมีขั้นตอน ดังนี้
ขั้นตอนที่ 1 แบ่งประชากรออกเป็นกลุ่ม ๆ โดยต้องแน่ใจว่าหน่วย ต่าง ๆ ในแต่ละกลุ่มมีลักษณะที่คล้ายคลึงกัน และหน่วยต่าง ๆ ภายในกลุ่มเดียวกันมีลักษณะที่แตกต่างกันออกไป ขั้นตอนที่ 2 สุ่มกลุ่มตัวอย่างบางกลุ่มออกมาจากกลุ่มทั้งหมด โดย สุ่มกลุ่มตัวอย่างด้วยวิธีการสุ่มแบบง่ายหรือแบบมีระบบ เพราะว่าประชากรในกลุ่มต่าง ๆ มีลักษณะเหมือนๆ กัน จึงสุ่มมาเพียงบางกลุ่มเท่านั้น ขั้นตอนที่ 3 สุ่มหน่วยตัวอย่างจากประชากรในกลุ่มที่สุ่มตัวอย่างได้ ในขั้นตอนที่ 2 โดยใช้วิธีการสุ่มหน่วยตัวอย่างแบบง่าย หรือแบบมีระบบ

59
แผนภาพแสดงการสุ่มตัวอย่างแบบกลุ่ม
ประชากร สุ่มกลุ่มตัวอย่าง สุ่มหน่วยตัวอย่าง แผนภาพแสดงการสุ่มตัวอย่างแบบกลุ่ม

60
ข้อดีของการสุ่มตัวอย่างแบบกลุ่ม
ช่วยเพิ่มประสิทธิภาพในการเลือกตัวอย่าง โดยช่วยลดระยะเวลาในการทำงาน และ ค่าใช้จ่ายในการเก็บข้อมูล เนื่องจากมีการเลือกกลุ่มขึ้นมาก่อน แล้วจึงเลือกตัวอย่างจากกลุ่มที่เลือก ข้อเสียของการสุ่มตัวอย่างแบบกลุ่ม เรื่องความผันแปรของหน่วยตัวอย่างจะมีมาก เนื่องจากหน่วยตัวอย่างในกลุ่มย่อยจะมีลักษณะที่แตกต่างกัน (Heterogenous)
")
61
2.4 Stratified Random Sampling
(การสุ่มตัวอย่างแบบระดับชั้น) การสุ่มตัวอย่างวิธีนี้ เหมาะสำหรับประชากรที่แบ่งเป็นระดับชั้น (Strata) โดยแต่ละระดับชั้นจะมีลักษณะที่แตกต่างกัน แต่หน่วยต่าง ๆ ที่อยู่ภายในระดับชั้นจะมีความเป็นเอกพันธ์ (Homogenous) หรือมีลักษณะที่เหมือนกัน
 การสุ่มตัวอย่างวิธีนี้ เหมาะสำหรับประชากรที่แบ่งเป็นระดับชั้น (Strata) โดยแต่ละระดับชั้นจะมีลักษณะที่แตกต่างกัน แต่หน่วยต่าง ๆ ที่อยู่ภายในระดับชั้นจะมีความเป็นเอกพันธ์ (Homogenous) หรือมีลักษณะที่เหมือนกัน.")
62
การสุ่มแบบระดับชั้นมีขั้นตอน ดังนี้
การสุ่มแบบระดับชั้นมีขั้นตอน ดังนี้ ขั้นตอนที่ 1 แบ่งประชากรออกเป็นระดับชั้น โดยให้หน่วยต่าง ๆ ที่อยู่คนละระดับชั้นมีลักษณะที่แตกต่างกัน และหน่วยต่าง ๆ ที่อยู่ภายในระดับชั้นเดียวกันมีลักษณะเหมือนกัน เช่น ผู้สำเร็จการศึกษาระดับประถมศึกษา มัธยมศึกษา และปริญญาตรี ขั้นตอนที่ 2 สุ่มหน่วยตัวอย่างบางหน่วยจากทุกระดับชั้น โดยวิธี การสุ่มตัวอย่างแบบง่าย เนื่องจากแต่ละระดับมีความแตกต่างกัน จึงต้องทำการสุ่มหน่วยตัวอย่างจากทุกระดับชั้น และในแต่ละระดับชั้นจะสุ่มหน่วยตัวอย่างออกมาเพียงบางส่วน ซึ่งอาจแบ่งเป็นวิธีการสุ่มตัวอย่างระดับชั้นออกเป็น 2 แบบ คือ

63
ต้องการหน่วยตัวอย่างทั้งหมด 1,500 หน่วย
แบบที่ 1 การสุ่มตัวอย่างในแต่ละระดับชั้นอย่างไม่เป็นสัดส่วน (Non Proportional Stratified Random Sampling) เป็นการสุ่มหน่วยตัวอย่างโดยที่ผู้วิจัยกำหนดจำนวนตัวอย่างในแต่ละระดับชั้นเอง ซึ่งจำนวนตัวอย่างที่กำหนดขึ้นมานั้น ไม่เป็นไปตามสัดส่วน ของจำนวนหน่วยทั้งหมดในระดับชั้นนั้นต่อจำนวนประชากรทั้งหมด เช่น….. 500 คน ประถมศึกษา 7,000 คน ต้องการหน่วยตัวอย่างทั้งหมด 1,500 หน่วย 500 คน มัธยมศึกษา ,000 คน ปริญญาตรี ,000 คน 500 คน
 เป็นการสุ่มหน่วยตัวอย่างโดยที่ผู้วิจัยกำหนดจำนวนตัวอย่างในแต่ละระดับชั้นเอง ซึ่งจำนวนตัวอย่างที่กำหนดขึ้นมานั้น ไม่เป็นไปตามสัดส่วน ของจำนวนหน่วยทั้งหมดในระดับชั้นนั้นต่อจำนวนประชากรทั้งหมด เช่น… คน. ประถมศึกษา 7,000 คน. ต้องการหน่วยตัวอย่างทั้งหมด 1,500 หน่วย. 500 คน. มัธยมศึกษา 2,000 คน. ปริญญาตรี 1,000 คน. 500 คน.")
64
แผนภาพแสดงการสุ่มตัวอย่างแบบระดับชั้นอย่างไม่เป็นสัดส่วน
ประชากร จำแนกระดับชั้น สุ่มหน่วยตัวอย่าง

65
แบบที่ 2 การสุ่มตัวอย่างในแต่ละระดับชั้นอย่างเป็นสัดส่วน
แบบที่ 2 การสุ่มตัวอย่างในแต่ละระดับชั้นอย่างเป็นสัดส่วน (Proportional Stratified Random Sampling) เป็นการสุ่มหน่วยตัวอย่างโดยที่ผู้วิจัยกำหนดจำนวนตัวอย่างในแต่ละระดับชั้น ตามสัดส่วน ของจำนวนหน่วยทั้งหมดในระดับชั้นนั้นต่อจำนวนประชากรทั้งหมด
 เป็นการสุ่มหน่วยตัวอย่างโดยที่ผู้วิจัยกำหนดจำนวนตัวอย่างในแต่ละระดับชั้น ตามสัดส่วน ของจำนวนหน่วยทั้งหมดในระดับชั้นนั้นต่อจำนวนประชากรทั้งหมด.")
66
ต้องการสุ่มตัวอย่างมาทั้งหมด 1,500 หน่วย
ตัวอย่างเช่น ต้องการสุ่มตัวอย่างมาทั้งหมด ,500 หน่วย ระดับชั้นประถมศึกษาจำนวน 7,000 คน มัธยมศึกษาจำนวน , คน ปริญญาตรีจำนวน , คน ดังนั้นควรสุ่มมาระดับชั้นละกี่คน ??? ระดับชั้นประถมศึกษาจำนวน = 7,000 x 1, = 1,050 คน 10,000 มัธยมศึกษาจำนวน = 2,000 x 1, = คน 10,000 ปริญญาตรีจำนวน = 1,000 x 1, = คน 10,000

67
แผนภาพแสดงการสุ่มตัวอย่างแบบระดับชั้นอย่างเป็นสัดส่วน
ประชากร จำแนกระดับชั้น สุ่มหน่วยตัวอย่าง

68
ข้อดีของการสุ่มตัวอย่างแบบระดับชั้น
ช่วยเพิ่มระดับความเที่ยงตรง โดยไม่ต้องเสียค่าใช้จ่ายเพิ่ม การสุ่มตัวอย่างแบบระดับชั้นจะสามารถรับประกันได้ว่ากลุ่มย่อยทั้งหมดจะถูกนำมารวมไว้ในกลุ่มตัวอย่าง โดยเฉพาะในกรณีที่ตัวแปรบางตัวของประชากร มีลักษณะการแจกแจงแบบเบ้ (Skewed)
")
69
2.5 Multi Stage Cluster Sampling
(การสุ่มกลุ่มตัวอย่างแบบหลายขั้นตอน) การสุ่มตัวอย่างวิธีนี้ เหมาะสำหรับ ประชากรที่มีขนาดใหญ่มาก หรือประชากรที่มีอยู่กระจัดกระจาย หรือผู้วิจัย ไม่สามารถสร้างกรอบของการเลือกตัวอย่างได้ การสุ่มตัวอย่างแบบนี้จะต้องทำการสุ่มตั้งแต่ 2 ขั้นตอนขึ้นไป โดยแบ่งประชากรออกเป็นกลุ่มใหญ่ๆ แล้วแบ่งเป็นกลุ่มย่อยๆ ต่อไปเรื่อย ๆ จนถึงกลุ่มย่อยที่เล็กที่สุด
 การสุ่มตัวอย่างวิธีนี้ เหมาะสำหรับ ประชากรที่มีขนาดใหญ่มาก หรือประชากรที่มีอยู่กระจัดกระจาย หรือผู้วิจัย ไม่สามารถสร้างกรอบของการเลือกตัวอย่างได้ การสุ่มตัวอย่างแบบนี้จะต้องทำการสุ่มตั้งแต่ 2 ขั้นตอนขึ้นไป โดยแบ่งประชากรออกเป็นกลุ่มใหญ่ๆ แล้วแบ่งเป็นกลุ่มย่อยๆ ต่อไปเรื่อย ๆ จนถึงกลุ่มย่อยที่เล็กที่สุด.")
70
การสุ่มตัวอย่างแบบนี้มีขั้นตอนดังนี้
ขั้นตอนที่ 1 สุ่มกลุ่มต่างๆ โดยแบ่งประชากรออกเป็นกลุ่มใหญ่ๆ และแบ่งกลุ่มใหญ่นั้นออกเป็นกลุ่มย่อย ๆ ลงไปอีกเรื่อยๆ จากนั้นจึงทำการสุ่มกลุ่มย่อยในแต่ละกลุ่มใหญ่ออกมา เช่น แบ่งประเทศไทยออกเป็น 4 ภาค คือ ภาคเหนือ ภาคตะวันออกเฉียงเหนือ ภาคกลาง ภาคใต้ แต่ละภาคแบ่งย่อยได้เป็นหลายจังหวัด ทำการสุ่มจังหวัดออกมาจากแต่ละภาค เช่น อาจสุ่มออกมาภาคละ 1 จังหวัด แต่ละจังหวัดแบ่งออกเป็นหลายหมู่บ้าน ทำการสุ่มหมู่บ้านออกมาจากจังหวัดที่สุ่มได้ เช่น สุ่มมาเพียงจังหวัดละ 1 หมู่บ้าน

71
ขั้นตอนที่ 2 สุ่มหน่วยตัวอย่างออกมาจากกลุ่มย่อยที่สุดของทุกกลุ่ม
สุ่มได้ในขั้นตอนที่ 1 เช่น หลังจากที่สุ่มได้หมู่บ้านแล้ว ให้สุ่มตัวอย่างจากหมู่บ้านที่สุ่มได้นั้นหมู่บ้านละ 10 คน สรุป... ขั้นตอนการสุ่มตัวอย่างนับว่าเป็นขั้นตอนสำคัญ ที่จะทำให้ ผู้วิจัยได้กลุ่มตัวอย่างที่เป็นตัวแทนของประชากรเป้าหมาย ผู้วิจัยต้องใช้ความรู้และวิจารณญาณ ในการตัดสินใจเลือกวิธีการใดวิธีการหนึ่ง โดยพิจารณาข้อดีและข้อเสียของ แต่ละวิธีด้วย

72
แหล่งความคลาดเคลื่อนของการวิจัยเชิงสำรวจ
1. ความคลาดเคลื่อนจากการสุ่มตัวอย่าง (Random Sampling Error) 2. ความคลาดเคลื่อนที่ไม่ได้เกิดจากการสุ่มตัวอย่าง (Non Sampling Error)
 2. ความคลาดเคลื่อนที่ไม่ได้เกิดจากการสุ่มตัวอย่าง. (Non Sampling Error)")
73
2. ความคลาดเคลื่อนที่ไม่ได้เกิดจากการสุ่มตัวอย่าง (Non Sampling Error)
2.1 ความผิดพลาดที่เกิดจากผู้วิจัย (Response Error) 2.2 ความผิดพลาดที่เกิดจากผู้ดำเนินการสัมภาษณ์ (Interviewer Errors) 2.3 ความผิดพลาดที่เกิดจากตัวผู้ตอบ (Respondent Errors)
 2.2 ความผิดพลาดที่เกิดจากผู้ดำเนินการสัมภาษณ์ (Interviewer Errors) 2.3 ความผิดพลาดที่เกิดจากตัวผู้ตอบ. (Respondent Errors)")
74
2.1 ความผิดพลาดที่เกิดจากผู้วิจัย
2.1 ความผิดพลาดที่เกิดจากผู้วิจัย (Response Error) (1) ความผิดพลาดที่เกิดจากข้อมูลที่ต้องการไม่สามารถหาได้ (2) ความผิดพลาดที่เกิดจากการวัดที่ผิดพลาด (3) ความผิดพลาดที่เกิดจากการให้คำจำกัดความของประชากรผิดพลาด (4) ความผิดพลาดที่เกิดจากการกำหนดกรอบตัวอย่างผิดพลาด
 (1) ความผิดพลาดที่เกิดจากข้อมูลที่ต้องการไม่สามารถหาได้ (2) ความผิดพลาดที่เกิดจากการวัดที่ผิดพลาด. (3) ความผิดพลาดที่เกิดจากการให้คำจำกัดความของประชากรผิดพลาด. (4) ความผิดพลาดที่เกิดจากการกำหนดกรอบตัวอย่างผิดพลาด.")
75
(Interviewer Errors) 2.2 ความผิดพลาดที่เกิดจากผู้ดำเนินการสัมภาษณ์
2.2 ความผิดพลาดที่เกิดจากผู้ดำเนินการสัมภาษณ์ (Interviewer Errors) (1) ความผิดพลาดที่เกิดจากการเลือกผู้ตอบหรือหน่วยตัวอย่างที่ผิด (2) ความผิดพลาดที่เกิดจากการตั้งคำถามที่ผิด (3) ความผิดพลาดที่เกิดจากการบันทึกข้อมูลที่ผิดพลาด (4) ความผิดพลาดที่เกิดจากการคดโกงคำตอบ
 (1) ความผิดพลาดที่เกิดจากการเลือกผู้ตอบหรือหน่วยตัวอย่างที่ผิด. (2) ความผิดพลาดที่เกิดจากการตั้งคำถามที่ผิด. (3) ความผิดพลาดที่เกิดจากการบันทึกข้อมูลที่ผิดพลาด. (4) ความผิดพลาดที่เกิดจากการคดโกงคำตอบ.")
76
2.3 ความผิดพลาดที่เกิดจากตัวผู้ตอบ
2.3 ความผิดพลาดที่เกิดจากตัวผู้ตอบ (Respondent Errors) (1) ความผิดพลาดที่เกิดจากการให้คำตอบที่ผิดพลาด (2) ความผิดพลาดที่เกิดจากการความไม่เต็มใจของผู้ตอบ (3) ความผิดพลาดที่เกิดจากการไม่ได้รับคำตอบ
 (1) ความผิดพลาดที่เกิดจากการให้คำตอบที่ผิดพลาด. (2) ความผิดพลาดที่เกิดจากการความไม่เต็มใจของผู้ตอบ. (3) ความผิดพลาดที่เกิดจากการไม่ได้รับคำตอบ.")


 จำนวน N สุ่ม (Random) กลุ่มตัวอย่าง (Sample)>")

น.พ.นภดล สุชาติ พ.บ. M.P.H.>")



>")

>")



 คือ อะไร>")
>")




